|
���пƼ���Ա�����㣬ʲô������������ϸ˵������
��Դ���й����ڵ��� ���ߣ���Ӣ ���ڣ�2017/6/5
(�й��������������������� ��Ӣ)
��������
����Ŀǰ���������ѳ��ȵ㻰�⣬������Ӧ�õ��о������ڽ��ڿƼ�����ӿ������ˣ���Ϊ���ڿƼ���Ա���˽��������ļ���ԭ�����б�Ҫ����������������صļ���(�㷨��˼��)Ҳ��ֵ������ѧϰ����ġ�������������֪ʶ�����ɻ���(�б��ϵ�����)�ǻ���ǰ�������о����Ļ����ϵģ�̫����������������;����������֪ʶ����ˮ����(�����ϵ��鼮)����ƪ��빵ط�����ȥXX������չ��Ӧ�ã����Լ������ò��岻����̫��ˮ��������Ӫ��Ϊ�㡣������������������ҵ��ʱ�������ӳ���Ա���ܹ�ʦ���ӽDZ�д��ϵ�п��ղ���--��Ϸ˵�������������������������ĵļ���BBS�Ϸ���������˺����������ɴ�ϵ�в����������ɡ�
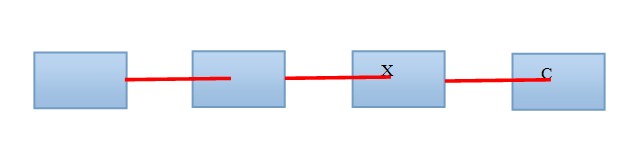
������1 �������Ļ����ṹ
�������������Կ���һ���������������ݽṹ�����Ƿּ�������������ۡ�
����1.1 ��������
���������ȿ���һ����Ҫ�����ݽṹ��������������ʵ���˸ýṹ�����磬C���ԡ�����ʽ���£�
����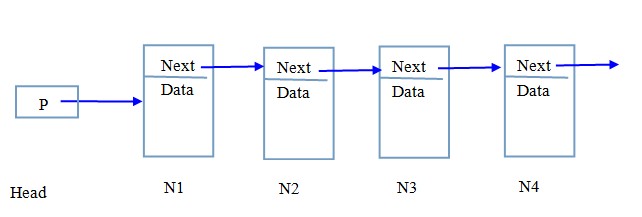
�������Ϻ����������������
����1���Խڵ��������ѯ(��λ)�ڵ㡢���ӽڵ㡢ɾ���Ͳ���ڵ㡢�����ڵ��λ��;
����2���Խڵ��е����ݽ��в������磬��Date(�ȶ�λ���ýڵ�)��
�������磬���ڵ�N���뵽N2��N3֮��
����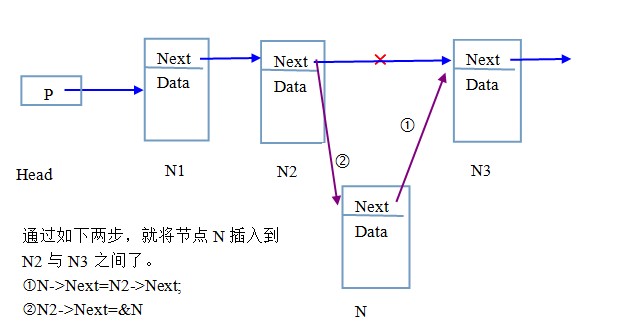
�������Կ�����������һ������ϵ����ݽṹ������Ϊ��������������Ƶġ�
�����������ǿ����෴�ij���������̽Ѱһ�����ݽṹ��Ҫ��������������������(���۸�)��
����������������ճ�������������ݿ��ָ��Ƕ�뵽��һ�����ݿ��У���Ϊ��һ�����ݿ�����ݲ��֣�������һ�����ݿ��ָ�Ƽ��㡣��ͼ��ʾ���������ν��������������������ͨ��������˵������
����
�������������������ṹ�dz���ͬ��
�������ȣ�ǰ��������ϵģ������ǽ���ϵġ������������ֽ���Ͻṹ��ʹ�ö����ݵ��ĺ����������κ����ڵ�ı䶯�����ᵼ����ָ�Ƶı䶯���Ӷ������Ҳ�����ڽڵ�����˱䶯�������ȥ���Ͳ�����������Ӧ�����κ����ڵ�ı䶯���������Ҳ�����нڵ���α䶯��
���������ǰ���ǿռ��еģ�������ʱ�����ϵġ�C�е����������Ƕ���Ϊһ���ڴ��е����ݽṹ�������ϵĽڵ�(��)�������������ƶ������磬��������ð�����������������κ������ڽڵ㣬�Ҳ�ڵ㲻�ܲ��������ڵ�֮ǰ����Ϊ�Ҳ�ڵ����������ڵ��ָ�ơ��ɴ˿ɼ����������ǰ�ʱ���Ⱥ��ϵ�������ӵģ�ʵ��������һ������ʷ����(�Ǻǣ�ǿ�ҽ��齫�任���������)��������ʷ�����������������Ϊ0���Ǹ����飬��Ϊ����������������ʷ��ֻ����ʱ����ǰ��(���������������Ҳ������µ�����)�������ܶ���ʷ�ġ�
������������ڷֲ�ʽ��������һ��ȱ�ݣ��������ؽڵ㶼Ҫ��������������������Խ��Խ������������Խ��Խ���ܷ��ڱ���ǰ������ʷ�����Ե�ǰ���£�����ڵ�ֻ������Լ���ص�������?
�������������ݿ��ָ���ص㣬��ʱ�����ǽ�ָ����Ϊ��������������������(key)�������������ҵ���ԭʼ������(value),���ǵĹ�ϵ��(key��value)���������������������֤��ԭʼ���������䡣�ڴ������£�����ڵ����ֻ����������Լ���ص����ݣ��Բ���ŵ����ݣ����Խ������������������Ϊ�����֣�����ͷ(�����ֽ�)�����ݼ�װ�䣬������ͷ���������������ݼ�װ���������������������ͼ��ij����ڵ��ŵ�������������(����������ص����ݿ�)��
����
����1.2 ָ�룬��ָ��
����C�е�����ͨ��ָ�����ӵģ���ָ����ǵ�ַ(ָ��ָ��һ�����ݿ����ڴ��д洢�ĵ�ַ)��ͨ��Ѱַ���Ϳ����ҵ�ָ��ָ������ݿ����ڴ��е�λ�ã�ʵ������λ�����ܡ�
���������ٿ����������е���ָ��������ô���¡���������������ȡһ�����ݼ���ָ�ƣ�����ָ�ƻ��ɾ����㰴����Բ��ָ��(��Ӧ���Ͻڵ�M)��
����
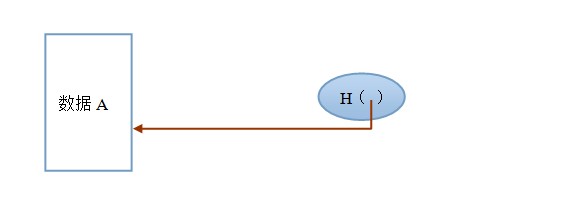
������ͼ������A(���ݿ�)ͨ����ϣ�㷨H��������ָ��a����������ָ��a����������������A�����������������������µ�ָ�ƴ����ŷ���������һ����������������е���ָ���������壬����������������(ָ��)�������ǿռ䶨λ����(סַ)��
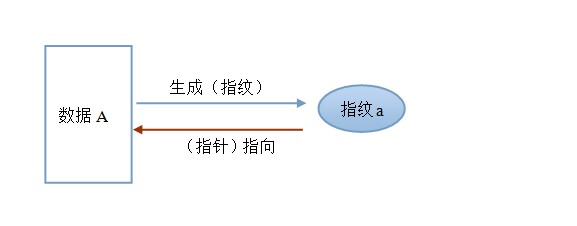
����A��Ӧ��a����˫�����壬һ����Ϊָ�ƣ�������Ϊָ�롣�������ù�ϣֵ �����������ָ������Ϊ��ϣָ�롣����Ǻţ�
����
������Ȼ����ϣָ�벢����ֱ��ʵ��ǰ��������λ�����ܣ������������˵�ָ�Ʋ�����ֱ�ӵõ����������˵����ƺ��롣������һ�㣬�е�������û����ϸ�룬��˵����ϣָ��ָ�����ݵĴ洢λ�������������ᵼ��ҡ����ǻ����Դ���һ��������˵���䲻��ȷ����һ������������A(���Ѵ洢���ڴ���)�����й�ϣָ��(ָ��)��û�б�Ҫ�������ϣָ��ֵ�������Ƶ�ָ��ָ����λ��;�������ϣָ��ֵ�Ǻܴ��(256λ)��Զ����Ŀǰ��64λѰַ�ռ�;��������ʹ���㹻��Ŀռ䣬��ô�ƶ����ݵ���ϣָ����ָʾ��λ�ã�����븽�������ݿ鲿���ص�?��C�У�������ϵͳ��������ڴ�(���ڴ������)���ٽ����ڴ�ĵ�ַ����ָ�롣
������Ȼ��ϣָ�벻��ʵ�������ڴ��еĶ�λ��������ij�ָ����ֶλ��ǿ���ʵ��ij�ֶ�λ�����磬��(a��A)��Ϊ(key��value)�������ݿ�ķ�ʽ����ʵ�ֿ��ٶ�λ��
��������a���������ֶΣ������ҵ���A��˵��aȷʵ���Կ�������ָ������ֻ����������ͨ�������µĵ�ַָ�롣
����1.3 �飬�ǿ�
������һ������ͼʾ���Կ�����������������һ����ֵ����г�������һ������ͷ�������ţ�ÿ����ͷ�����һ�������ݼ�װ��������װ����װ�����ݡ�������ǿ��������֯��װ��������ݡ�
����ǰ�����ǽ����κ�һ�����ݿ������Hash��������ָ�ƣ����ָ�Ʒ�������Ϊָ��(Hashָ��)ָ������ݿ顣����Hashָ��Ӧ�������ṹ������÷�˶���(�Է�����������Merkle tree)�������������Ҫ����֯���ݼ�װ�������ݵ�������ϡ�
�������ǿ���÷�˶���������
����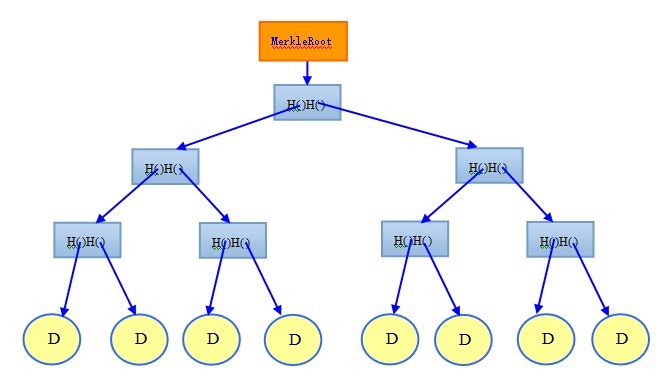
����Ҷ�ӽڵ�Ϊ����D�������Ƕ�������������ڵ㺬����Hashָ�룬�������ĵ�һ��1���ڵ㡢�ڶ���2���ڵ㡢������4���ڵ㡢���������Ϊk+1��(��Ҷ�ӽڵ���k+1��)����Ҷ��(����)����Ϊ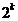 �� �Ӹ���Ҷ���辭��k��ָ�롣������������֪Ҷ��(����)����Ϊn����Ӹ���Ҷ���辭�� �� �Ӹ���Ҷ���辭��k��ָ�롣������������֪Ҷ��(����)����Ϊn����Ӹ���Ҷ���辭��  (��Ϊ2)��ָ�롣 (��Ϊ2)��ָ�롣
��������Hashָ���ָ������֪��Ҷ�ӽڵ�(����)�ı仯�������ݵ����ڵ㣬���κ�һ��Ҷ�ӵı仯����������ڵ�ı仯����֮��ֻҪ���ڵ�δ�仯���Ϳ�����Ϊ����Ҷ��(һ������)δ�ı䡣
�����ص��Ͻڵ����һ��ͼ��������Hash(dz��ɫ��)Ƕ�뵽����ͷ�У��䵱�������(MerkleRoot)�������ݼ�װ����һ��÷�˶����������鲻������������һ��Merkle ����������Ȼ����Merkle���������ݴ��(�����л�)���ǿ��Ա���������ġ�
����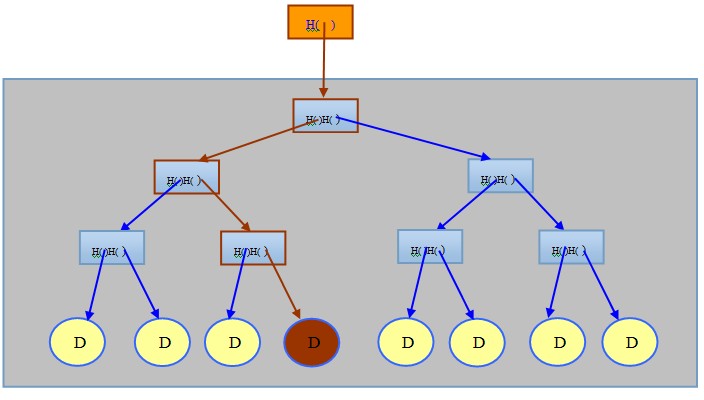
����1���������С������֤�ڵ�D������Ҷ��
���������֤��÷�˶�����һ��Ҷ�ӡ���Ȼ���㲻��Ҫ�ṩ����������ֻ���ṩҶ�ӺʹӸ�����Ҷ�ӵ�·�����ɣ��� 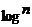 ��ָ��ڵ㣬�������ʱ�临�Ӷ�Ϊ ��ָ��ڵ㣬�������ʱ�临�Ӷ�Ϊ 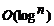 ����ͼ����ɫ��·���� ����ͼ����ɫ��·����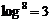 �����ṩ3��ָ��ڵ㡣 �����ṩ3��ָ��ڵ㡣
������֤����(�ӵ�������֤)����ɫ����D��Hashֵһ������һ��ڵ����ݵ�����ұߣ��ýڵ�Hashֵһ���Ǹ���һ��ڵ����ݵ�����ұߣ���ֱ�������ٵ������
������һ���Ա���������Ը�����Ҫ��һ������ȱ�����������磬��ֻ������ͼ�к�ɫ���ݣ���ֻ�����Ÿ����ݼ�·������Ȼ����Ҫʱ����Ҳ������������ȱ������(��ʵ��ֻ��Ҫ�������)�����������һ��������Ӷ�(���)���£����ù�ϣָ���ҡ�
����2������жϽڵ�D��������Ҷ��
����Ҫ֤��һ������D������ij��÷�˶�����Ҷ�ӣ���û����ô���ˣ���Ҫͬ��÷�˶�����Ҷ����һ�Ա�(��Ա���ָ��)����÷�˶�����Ҷ���ǰ�ij�ֹ���������ʱ�����Ż��ɣ�ֻ��Աȵ�����D��������Ӧ����λ�á�
����3����÷�˶�����������Ҳ����
������Ҫ�ĺ�ɫ����D������Ҫ��������·�����ĵ�����������������D��ʼ������������������һ�����ӵ�������Ϊ�����е�Ҷ�����ݵ��Ķ��漰�����������ʼ�����֧�ֶ�Ҷ�ӵIJ�����(������������������Ҫ�ȴ�)����Ȼ��������÷�˶�����Ϊ�����������������У��Ǹ����IJ��ˣ���Ϊ�����������ı仯��������������ı仯����һ���أ��������������Ҳ�����������Ӧ��
����4����һ�����ϵ�һ��Ҷ��֮���������С�����ع������?
�����ع�ʵ�������Ե���������ͼ�к����ϵĺ��Ȼ����D��1��2��3����Ȼ����ֻ�ǵõ�һ������ʵ���ϣ�����Եõ����������Ϊ��������ֵ�����ϵ��care�����ԣ�����ij�������H()�����������ϼ��㣬���õ���һ��������Щ�����Ƿ���Ҫ��ġ�
����ǰ�������˶���÷�˶������´˿��ƹ㵽���÷�˶�����Ҫ�㣺
����1�����㼶����������ͬ�����������ͺܹ��������ڴ���;
����2���������ݰ�(�磬��������)���Ƿ���Ҷ�ӽڵ㣬��Ҷ�ӽڵ����²�ڵ��Hashָ��(��);
����3��һ��Ҷ�ӽڵ���ԷŶ�����ݰ�������Ҷ�Ӷ���Ϊ���ݰ�����(Ͱ)��
�������ϣ������е�������һ��÷�˶�������Ȼ���������л�����Ա�Ϊ�����ݿ�����
����1.4 ��ʷ�����ܳ�Ϊ��ʷ
�������ù�ϣָ�룬���ǰ�����ݣ��������»�һ����������ע����ͷΪָ�뷽�������������ɷ������ͷ�෴�����⣬��Ȼ������ʷ��������ʱ���(time stamp)�ز����١����ˣ�ȷ������ͷ�е������������Ԫ�أ�ʱ���(Timestam)��ָ��ǰһ����(, ͷ)��ָ��(Pre-Hash)��ָ�����ݿ�(÷�˶�������)��ָ��(MerkleRoot)��

����ƽʱ������˵������ʷ��Ϊ��ʷ��������˼��˵������ʷ��һ�߰ɣ�����仰�����������в�ͨ����Ϊ��������������������ʷԭʼ����������˫��֧��(����ר�Ż������漰)����������ն������������ˣ�����ʷ�����������ȶ����������в�ͨ���ɴ˴����������ǣ�����ʱ������ƣ�����Խ��Խ�Ӵ�(��Ҫ�������Ĵ洢�豸��ֻ�мӷ�)������ķ�ΧҲ��Խ��Խ��(���½���Ч�����½���ֻ�м���)������������������������˫�������£��������������ջ�������������Ȼ�������µ���������������ˣ����������������ڼ䣬�����������ʷ�������������ʣ���������֧����Ҫ������ʷ�����������Ĵ�������Ӧ��(��һ��ȱ��)��
����������������ʷ�������������������Dz��ܱ��۸ĵģ���ʹ���ݴ���Ҳ�����ģ��ӽ��ײ��潲�����ǽ��ײ��ɳ���(û�з����ͳ���);����ũ�ǶȽ�������BUG��Ӱ�쵽���ݣ����鷳�ʹ��ˣ����ݲ�������ά���������ŵ�(����Ҫ�ⷽ���ά����Ա)Ҳ��ȱ��(���ܸĴ�)����������ҵ��ͳ����������Ҫ�����(�ڶ���ȱ��)��
����ǰ�棬����֪����ϣָ����һ���ص㣺��������A����ָ��a�������ɷ�����ָ�����෴���ɴ�Merkle tree�����ɹ������Ե����ϣ�������Ҷ���ϣ�ÿƬҶ�ӵı仯�����������ֱ��Ӱ�������������������ȵ�������һ���Ծ�����Merkle tree������֧�ִ�������(������ȱ��)�������ر�û����÷�˶�����Ҷ�Ӵ��˻��Ŀɱ���Ϣ(�����)���Ӷ��ܿ�����һȱ�㣬���ǽ�����������(����)��Ϊ÷�˶�����Ҷ�ӡ�����Ϊ�������ϲ������ף����������׳���(����)��Ȼ��ӳ�����ȡ��һ�������Ľ��ף�һ��������÷�˶�������������������У�������֧�ִ��������ġ�������֧����������������(��Aת�˸�B��B����ת��C)��ԭ����������ĸ�ȱ�㡣
�����������������Ϊ����������ô�������ȴ�����Ҫȫ����ɹ�ʶ�����ر��趨�����ȴ���ʱ����һ��Сʱ��������������ȴ���ʱ��ʹ��������ҵӦ�ò��ò���������������ѡ��ͬ��������������Ҫ���ȴ�����ʶ������֧��ǿʵʱ��Ӧ��(���ĸ�ȱ��)��
������2 ����������ѧ֪ʶ��
���������������Ǹ�ֲ������ѧ�ģ��������Ƕ��漰��������ѧ֪ʶ�����ռ��Խ��⡣
����2.1 �˹�ϣ��DZ˹�ϣ
����ǰ�棬���ǽ�a(A�Ĺ�ϣֵ)��ΪA��ָ�ƣ���a��Ψһ����ȷ����A������ָ��֤����Ψһȷ���ﷸһ����
��������ϣ���Dz�İ�����磬��5̨������������ϣ����������5̨�ϽϾ��ȵطֲ�(���ؾ���)������������涨����ij������x(�磬������š������˺š��������ʱ��ȵ�)�ͷ�������ij������y(�磬���������0��1��2��3��4)������һ����ϣ���� y = x (mod5)�����������ԣ�������x���䵽������y�ϡ�
������ϣ���� y = x (mod5)���ڷ���������ӳ�����ã���ͼ����7�Ž���12�Ž������䵽2�ŷ������ϴ�����
������Ȼ���ù�ϣ���������������ԣ�
����1��������7�ܵõ�2������2���ܶ϶���7
����2��ѹ������������(��ǧ����Ľ���)���䵽��������(5̨)�У��Ҿ��ȷֲ���
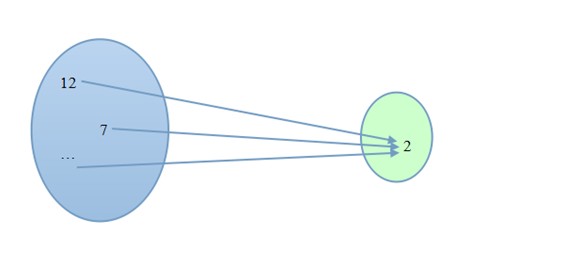
����7��12����Ӧ��2������˵7��12��������ײ�����ؾ�����������������ײ���ԡ�ֻҪ��ѹ���ͻ������ײ����ʹһ����ѹ��������ԭ��������˵�ģ�n+1ֻ���ӷ���nֻ���ӣ�һ����һ������������ֻ(������)����(��ײ)������˵��һ��������������С��������ʱ��������һ��������������ij�ָ��ʷ�����ײ���磬40ֻ���ӷ���365ֻ���ӵ������
��������������ԣ��ٶ���С����40��(����)������С������������ײ��(ͬһ�������)��(ʲô?С�鲻��40��?��������Ů��������)��(ʲô?���뱩¶����?�������㲻����ֽ��д�ϼ�����)��
����������ײ���и��ؾ��⣬����ײ��ָ�Ƶ����У�������ָ������ײ���ǻ�����������Ϊ֤���֤��ô?��ϣ������ѹ������˵����ϣ�������߱�����ײ���ԣ���������һ������һ������Ӧ�÷�Χ���ڣ��Ҿ�������ײ�������Ĺ�ϣ�����������ϣ���������棬��Ȼ�ù�ϣ����H���ڵ���ײ������1����ʹ������Ӧ�ó�������������;2�����������Ѷȴ�(�����ϲ�����)��
������������Ӧ��ʱ���Ϳ���Ϊ�����������ײ��������ϣ������������ײ�������ϣֵ�Ϳ�����Ϊ������ָ�����������֪��MD5��������һ����ϣ���������磬����MD5���汾���ļ�������ָ�ƣ�������֤�汾/�ļ��Ƿ۸�(�����ص��ļ���֤������ָ���Ƿ�Ϊָ����ֵ)��汾�Dz������µġ������ҵ���MD5ǿ�Ȳ���(����128λ)���ҹ�����ѧ����С���ҵ���MD5������ײ�ķ���(�����������������������Ѷȴ�����ǰ��)��ֱ�ӵ�����MD5����̭�����á���λ�����ࡢǿ�ȸ��ߵ��㷨���档
����2.2 ��ײ������
�����Ͻ��ô������������ײ�����ԣ���֪��Ҹо����?�����ҿ�ʼʱ��ֱ���ϸо�40����ײ���յĿ����Ժ�С(�Ͼ���365��)����ʵ�ϣ�40����ײ���յĿ�����(����)�ɴ�89%���������ﵽ100��ʱ��ײ���յĿ����Լ�����100%(6��9)��ֻҪ�����ﵽ23��ײ���յĿ����Ծͳ���50%��
������ײ�������ķ���������ײ����������ײ�������ĸ��ʵ���1������ײ�������ĸ��ʣ�������ײ�������ĸ������㣬��k���ˣ������Dz�ײ���յĸ���Ϊ
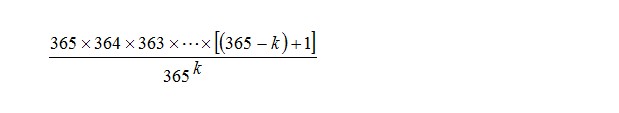
�����ɴˣ����ǿ��Եó�һ�����ۣ�1��(����)ѹ������һ���������ײ;2����ʹ������Դ����������������ײ�Ŀ����Ի��Ǻܸߵġ���ô��ô����������ײ��������?
�������ǻص��Ͻڵĸ�������������ֱ�۵�����һ�²�������ײ�������ķ�����
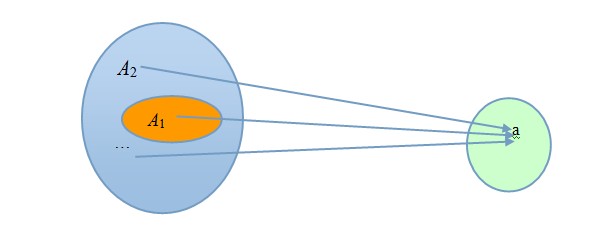
�������ȣ�����Ӧ�����ұߵļ���(Ŀ�꼯)������������������;
������Σ�����Ӧ��С��ߵļ���(Դ��)��������Ӧ�ó�����ʹ��������Ҫ���������Ӽ���(��ͼ��ɫ)ԶС���ұ�Ŀ�꼯����С��ʽ������ά�ȣ�һ�ǿռ䣬�磬���ǵ���������һ����ʽ�ͱ���Ҫ��ģ�����ų��˲��ϸ��;����ʱ���ϵģ��磬һ������ij�����������ڵĽ���һëǮ��ϵû�У���ȫ�����������ָ��շ�������ײ��
�������磬һ��ֻ���(��ɫ��)��������100ֻ����(��ɫ������Ӧ�õ������Ӽ�)���������һǧֻ����(�ұ�Ŀ�꼯)�������Ϊ����û������ײ��(û����ֻ������ͬһֻ������)������������ֻ���ӽ���ͬһֻ���ӣ������������Ƿ��ޣ����Ҫ���ƷɵĹ���
�������������㷨(��Ϊ)�Ϲ���취��������ķ�����������磬һֻһֻ�طŷɣ�����֪�������е������
���������������㣬���α�Ϊ��
��������� > > ������ > > ������;��ɢ�ķ�����Ϊ(�㷨)��
������ > > ����ʾԶԶ���ڣ���һ���� > > ������������Ե���ײ(������ԭ��)���ڶ����� > > �������ż����ײ(��������ײ)���ټ����㷨����������ײ��������
�������������Ӿ���������ײ�������Ǿ�˵���Ͽ���ײ��(������ײ����)���������������ײ������Ϸ˵���еļ������⡣
�������ϸ�ؽ���(��һ������ѧ���ϸ������)��Ϊָ�Ƶ�Hash����Ӧ���е����ʣ�
��������ѹ���ԣ��������Ϊ����ij�����Ϣ�������Ϊ�̶����ȵĶ���ֵ��(��128��256����);
���������������ԣ���֪����x��������Hashֵh(x)���ף�����֪Hashֵh��Ҫ�ҵ���Ӧ��x�ڼ����ϲ�����;
��������������ײ�ԣ������������x���ҵ����� ����h(x)=h(y)��y�ڼ����ϲ�����;
������������ײ�ԣ��ҵ���������h(x)=h(y)��ż��(x,y)�ڼ������Dz����еġ�
�����ص��������е�����ָ�ƣ�ѡ�õ���HASH-256�����Ƿ����������ʵ�Hash����(256λ)����˵Ҫ�ƽ�����Ҫ�ȵ����Ӽ����֮��ij�ǿ�������֡�
������������������ײ������������Ϊ����A������Hashֵa��һһ��Ӧ�ģ����������������ۻ�ʯ֮һ����������ϵ�2�ڵ����ݣ���ϣֵ���������о����������ã�
����1����Ϊָ�ƣ����ڷ��۸�;
����2����Ϊָ�룬���ڲ�ѯ��
����ע��һЩ���»���ͷ��ʱ��û��ע������֮�����������ɻ��ң��Ķ�ʱ��ע����һ�㡣

����2.3 ����?ʵ����ǩ��
����ǰ������˵������������������ʹ������ѧ��ָ�ƣ����������ٿ����ڽ�����ʹ������ѧ��ǩ����
��������֪�������ױ����з�α��ͷ��������ճ������п�ǩ����������֤����ֽ��������ʹ�����������ǩ������Ȼ����ǩ���������룬��Ϊ����ǩ������ʵ��ͬ��������������ͬһ���ˣ���ͬ�Ľ��ײ���������ǩ����ͬ��
��������ǩ�����Կ�������дǩ���Ļ������������ƣ�
����1�����ܷ���ؽ���ǩ���������ҵ�˽Կ��������ǩ��;
����2�������ܷ������֤���ҵ�ǩ�����������ҵĹ�Կ���ҵ�ǩ��������֤����ͨ�������ҵ�ǩ��������Ϊ��ð;
����3��ǩ�������ض������ݰ�(���ܴ۸�����)�������ݲ���ǩ�������㣬��ǩ�����̵�����������(��Ϣ)��˽Կ;
����4��ǩ��Ҫ����Ч�ʣ���Ȼ���ֹ��Զ�ҳ��ͬ��ÿҳ��ǩ����Ч�ʲ����Ƚ�����ѹ����һҳ��ǩ����������֪��Hash������ѹ�����ܣ����Զ�ѹ���������ǩ�������䲻�DZ���ĵ�����Ҫ�ģ���Ϊ��ǩ���㷨������ʱ���ϻ�����ǩ�����ݳ��ȳ�����;
��������(��Ϣ)ͨ��Hashѹ�������ϢժҪ(�Ͻ�����֪��Hashֵ������������2�����ã����ǵ�3�����ã���Ϊ��ϢժҪ����������ǩ��)������������˵��ǩ��������ָ����ϢժҪ������ǩ����
��������ǩ��(Ҳ�е���ǩ��)���Dz���İ�������磬֤��(U�ܺ�����֤��)������Կ֤�飬����һ������ǩ��������������Կ���ض�ʹ����(����ˡ��豸�����)����ʹ�����ṩ��Կ��ʹ�����ڽ��м��ܵȡ���Ҫ��վͨ���Ὣ����֤��䷢���ͻ���(���ء���װ���Զ�����)�������������У�certmgr.msc���Ϳ��Կ���������е�֤�飬�㿪һ��֤�飬�����������ϸ��Ϣ���п������䷢�ߡ���Ч�ڡ���Կ��ָ�ơ������㷨�ȡ�
�����Ƚ�һ��(�ǶԳ�)���ܺ�ǩ������Ȥ(����)��
����1��������ǩ����Ӧ���������Լ���˽Կ��������˵��ʹ��(�Լ���)˽Կ��Ҫô�ǽ��ܣ�Ҫô��ǩ��;
����2����������֤��Ӧ�������ñ��˵Ĺ�Կ��������˵��ʹ��(�ñ��˵�)��Կ��Ҫô�Ǽ��ܣ�Ҫô����֤;
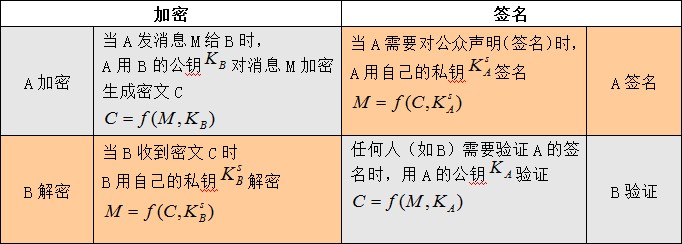
�����������еĽ����ǻ�������ǩ���ģ����ر�֮��ĵ��ӻ��ҳ���Ϊ���ܻ��ң�ʵ����������ǩ�����ҡ�
������3 ���ṹ
������������������װ�����ģ���ô�����ڲ��Ľṹ���?��صĽ�������ι�����?
����3.1 ��ַ?ʵ�����˻�
��������֪������Aͨ�������ʽ�ת��B����A��Ҫ֪��B���˻�����ô��ʲô����B���˻���?��B��ο���?�ٶ��������ڹ����Ϲ������У���ô����������˽�Ĵ�ʩ�ͺ���Ҫ����Ȼ��BӦ����ij���������������Լ�(���˻���)����ô�����ȡ����������?
��������ѧ�������ǣ�B������CA����һ�Թ���˽Կ���������������Թ�Կ��Ϊ������������������ʱ��A��B�Ĺ�Կ(��������)ת���ʽ�B��˽Կǩ����ȡ�ʽ�
������ô���������ˣ���Կ��Ϊ��������̫����������Щ����������������Ż�(����Ż�˼·ֵ�ô��ѧϰ)��
����1������Կѹ��;
����2������У��λ;
����3�������;
������Կѹ����Ȼ�����õ�Hashָ��(ȡ160bit)���ٽ�ָ�Ʋ���ij�����㣬��ȡ�ֲ�(��ȡͷ4Byte,��32bit)��ǰ���ټ���0x00(4bit)����ʱ����Կ�˻���Ϊ196λ��0��1����������ǿ���Hash�ĵ�4�����ã���Ϊѹ�����������ڲ������˻�����
����ͨ������ͷ�������õ�һ����0��1�����������ص㽲����3��������д��������ơ���ƴ��������֣�
l ���ô���ƣ���������ʽ�ij���;
l ���������ַ���
����0��1���Ƕ�����(��С����)������������ת��Ϊ�������ƣ��磬�����Ϥ��10���ƺ�16���ơ��磬10���Ƶ�179��

������������֤�������ʽ��
��������֪����
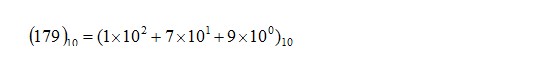
ʵ���������������е���Ҳ�����Ա�ʾ��ʮ�ƽ������Ķ���ʽ(��Ϊ����)��������һ���T���ƣ�T�����е�kλ��

�������У� ��һ�����ż�����ȡֵ��������ż�������T���ַ�����С����ֱ����0��1��2������ �����磬ʮ����Ϊ0��1��2������9��ʮ��������Ϊ0��1��2������9��A��B��C��D��E��F
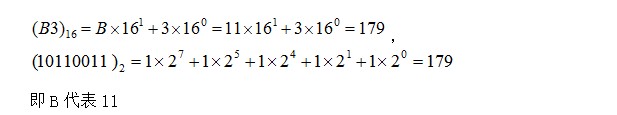
����������������ǿ��Եõ��������ۣ�
����1��һ������������������ʽ����ͨ������ʽ�ڸ�������ת��;
����2������Խ����Խ�̣���Ȼʹ�õ��ַ�Խ�࣬����T�Ĵ�С������ʹ�õ��ַ��ĸ�����
�����������Կ��ǣ������Խ��Խ�ã����Ҫ�����Ǿ����ܶ��ѡȡ�����緶Χ�����Ϥ���ַ����������ǹ���������ż����������������ַ�(10��)+Ӣ���ַ���д(26��)+Ӣ���ַ�Сд(26��)=62�������м������ڻ�����Ӧ������0��o��O�����б���o����I��1��l�����б���1�������������ĸ���62-4=58���ַ�����Ϊ�����������ĸ��������룬������ˣ��ַ�1��Ӧ���Ϊ0�����Ҷˣ��ַ�z��Ӧ�����Ϊ58�������Base58�������
�������øñ���������������ʽ�������ɽ�ǰ����200λ0��1���˻�ת����58��������ת����Ϊ34λ���ַ�������������롣ת����Ľ����Ϊ��Կ��ַ���õ�ַ������ͨ�ĵ�ַ(�ڴ��ַ�������ַ)������ҵ��Ƕȵ����˻�����
��������Ϊ��ȡ��Ϊ����ַ�����к�ʵ�ʣ��������ʼ���ַ���ʼ��ĵ������������ܾ���ǰ��ͨ���ʾֻ�Ҳ��ʹ���ʼ����ʵ�������ַ�������ƣ����﹫Կ��ַ��ָ�ʽ���������ƾ˽Կ�����ʽ𣬼������Ӧ��˽Կ����������˭ӵ�и�˽Կ������ͳ�����˻��������˒����ġ����⣬������Ҳ������������(�ʽ�)���������ڹ�����ת�������ʲ������ԣ���Ϊ����ַ�����Ƿ�Χ��������ַ�������������������
��������������ϵ�У�û�н���������������ʵ����Ķ�Ӧ��ϵ����û���û���֤���ƣ������ǣ�ֻ����˽Կ��֤��������������һ���棺һ������ȡ�����˽Կ���������������������Ϳ���ʹ������ʽ���;��һ���棺���˽ԿŪ����(����)�����֤�����������������������ʹ���DZ��ʽ��ˡ�
������ҿ���̫���˰ɣ�������(˼����)��
����1�����ǵ��˺���19λ�����������Base58��������Ϊ��λ?
����2��������Ĵ���Nλ����34λ�Ĺ�Կ��ַ̫�������ѹ����Nλ?����������ˣ�����ʲô���?
����3.2 ����
��������������һ���µ������������
��������һ�����ʽ���ת���̣�ij��Xָ��һ���ʽ����(A)��‚‚����ȡ����ʽ�;ƒƒ�㽫�ñ��ʽ�ָ��������B(ʹ�øñ��ʽ�)��
�������������У���Ȼ������X�Ĺ���;��‚‚������ƒƒ������A�Ĺ�������ͳ˼ά�У������ǽ���‚‚������ƒƒ�������������ף����µ�����������������㾡���ܵ��Ƴ�����ȡ����ֻ����ʹ�øñ��ʽ�ʱ����ȡ�ñ��ʽ𣬽�����ȡ������ʹ������Ϊһ����������
�������ף���������һ��������Ļ������ټ�һ�䣺��һ��ȫ���������ٶ�ij��ͨ������1ʹA�����һ���ʽ����ڣ�Aͨ������2���������������������ȡ�ñ��ʽ�ͽ�����ʽ�ȫ��ָ����B��
�����������ٶ��ǣ���ͨ�������εĵ�����(����)��A�Լ������ײ������չʾ�����ǿ��콻��2��Ҫ�ء�
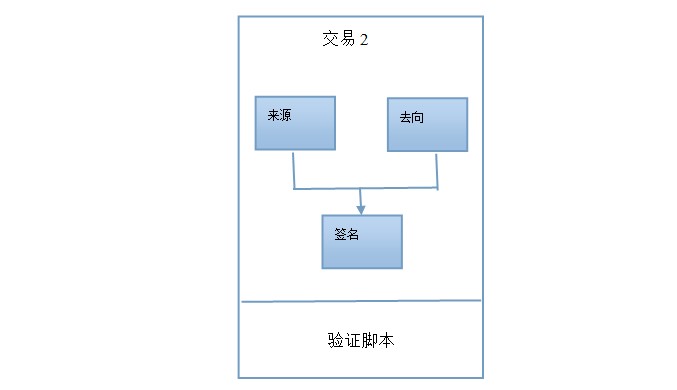
��������Դ��������ʽ���Դ�ڽ���1����ǰ���½ڿ�֪������1��ָ�ƾʹ�������1�����ԣ�����Դ���Ǹ���ϣָ��(ָ��)��ָ����1�����ڲ���ͨ�������εĵ����������ܼ�˵������Դ��=A�ͽ�����X����ð��A����A�Ľ�
������ȥ������ȥ��Ȼ��B����������չʾ����ң���B��ϣ��ʵ���ƣ����ʱ������B�Ĺ�Կ  ����B(ʵ�������ϽڵĹ�Կ��ַ)�� ����B(ʵ�������ϽڵĹ�Կ��ַ)��
������ǩ����������2��A���ģ�Ϊ�˷�α��ͷ�������������A�Խ���2�Ĺؼ�Ҫ�ؽ���ǩ����ͬʱ��A��ǩ��Ҳ��ʾ���Խ���1(ָ��)Ҳǩ���ˣ�����ʾ���Խ���1��ָ��A���ʽ����ȡ��
��������֤�ű�����������ͨ������֤������֤��ƽ̨��һ���������������ݽ�������������֤�ű��������ǽ���Աд�ġ���������������Ǵ��룬�Ǻǣ�������Ա�Dz���һ�¸ߴ�����?���뼴��������
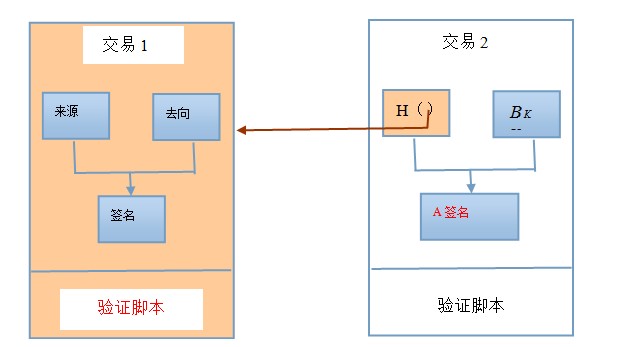
����Xͨ������1���ʽ�ת��A(���ѵõ��˴�ҵ��Ͽ�)��Aͨ������2���ʽ�ת��B�������Ҫͨ������֤�ű�������֤����2�ĺϷ��ԡ�����2����A���ģ�����Aǩ���ģ��������֤��������֤�ű������ڽ���2�У�������֤�����ɣ�ʵ���У�����֤����2������֤�ű������ڽ���1�У��൱��X���ʽ�ת��Aʱ�����˾䣺ƾA��˽Կ��ȡ����ʽ�(������2��Ҫ��A�Խ���1ǩ��)��
����Aͨ������2�������ȡ����ʽ��õ�����ʽ�������ǰ����A��ʱ�ǵ�˽Կ��һ��������˽Կ����A��ʧȥ�����ʽ�(�������˽���2)���������һ�˽Կ����Ҳ���������Ͻ�˵���������е��˻�(��ַ)û���û���֤���ơ�(�������еĵ����ȱ��)��
����3.3 ���ܺ�Լ
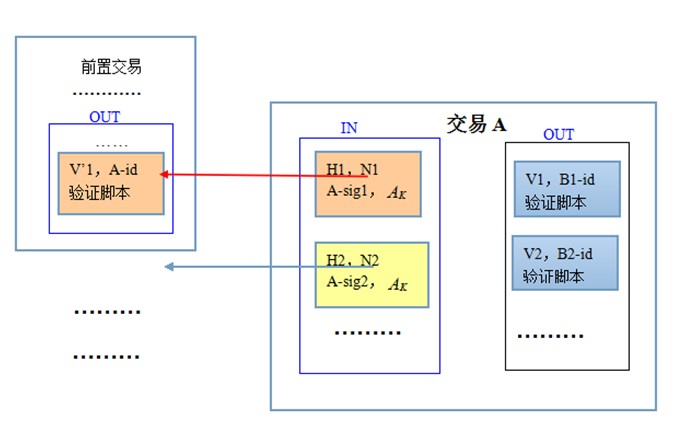
����������һ�ڣ����ǽ�����Ϊ�����֣���ǩ����������Դ��(IN)��������֤�ű���������ȥ����(OUT)��������Ӧ�ı��Σ�
����1���ʽ��������1�е�OUT����(�뽻��2��ص�)��A_id��A������ַ��(��A�Ĺ�Կ ���εõ�)���ǽ���1ָ�����ʽ�ת��A������2��OUT���ֱ���A�ֽ��ʽ�ת��B(��ַΪB_id)��
����2��ǩ����Ч��������2��Aǩ������MessageΪ�����֣�����2(ȥ��(Aǩ���� ))�ͽ���1�е�OUT����(�뽻��2��ص�)������ǩ����һʯ���Խ���1��OUT����ǩ��(������ǩ������)���Խ���2ǩ������������2��A��(�������ʽ��˭)�� ))�ͽ���1�е�OUT����(�뽻��2��ص�)������ǩ����һʯ���Խ���1��OUT����ǩ��(������ǩ������)���Խ���2ǩ������������2��A��(�������ʽ��˭)��
����3��IN�У�����(��Կ )������������˭(����Ҽ���)��
������ν��֤������(����������2��A)��������������������1��ǰ���£��ó���(���˹�)�Խ���2�ĺϷ��Խ�����֤���������֣�
����1��������֤������2�е� �ǽ���1ָ���Ĺ�Կ��ַA_id;
����2��ǩ����֤������2�е�ǩ������A��˽Կǩ����˽Կ�������㣬������ù�Կ ����֤ǩ���� ����֤ǩ����
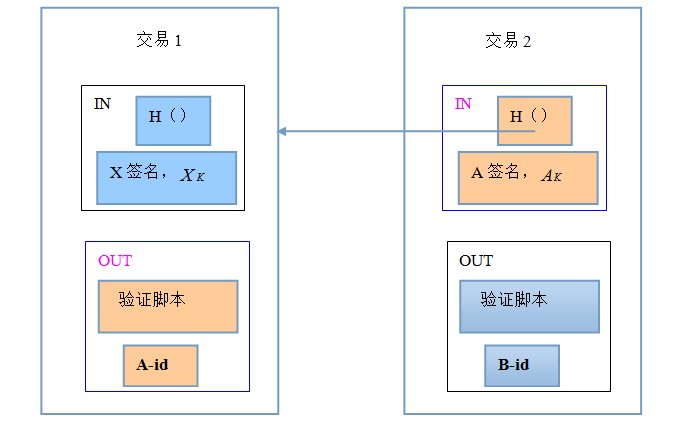
�����������������ǿ������һ���Ľű�(�����ݺ�ָ�����)���ýű�Դ�ڽ���1��OUT(�������ʽ��˭)�ͽ���2��IN(������ǩ������)�����ű��Զ�ջ��ʽ���������轫������������
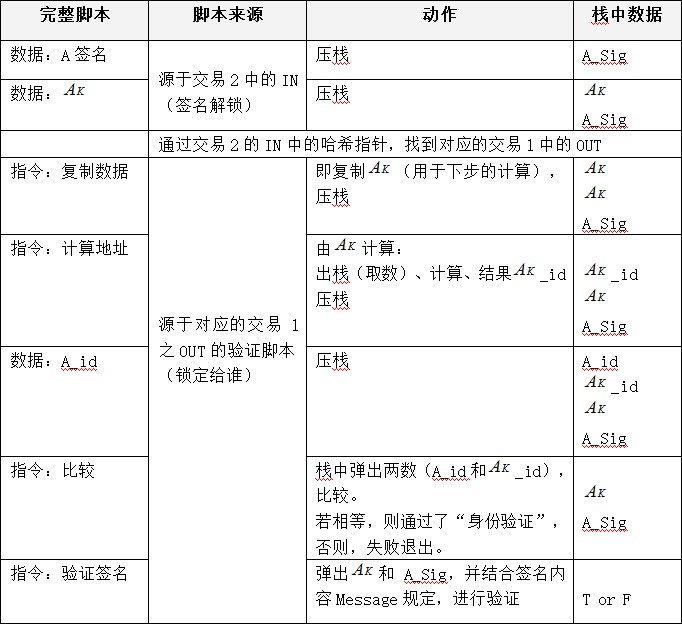
��������ű�������ν�������ܺ�Լ����ʵ�����ǽ��������ֺ�Լ��+����֤�ű������ټ������е�ƽ̨����(�磬����ջ���з�ʽ)��
����3.4 ��Ͻ���
����ǰ�����ǶԼ������˷�������ν����������ָA���һ���ʽ�(����1��)��ǰ���£�������ȫ��ת��B�����ڽ�������չΪ��A��ǰ�ѻ���˶���ʽ�(��ǰ������)��������ת����ͬ����(�����Լ�)��
��������ǰ���Ľ�������Ƴ�IN��OUT�����ֵ�˼·����һ���ؽ�IN��OUT��Ƴ�����Ϳ��Խ�����⡣
��������ʱA���Ľ���Ϊ������A�����Աȼ���ʱ�Ľṹ�����ǿ�����չ��
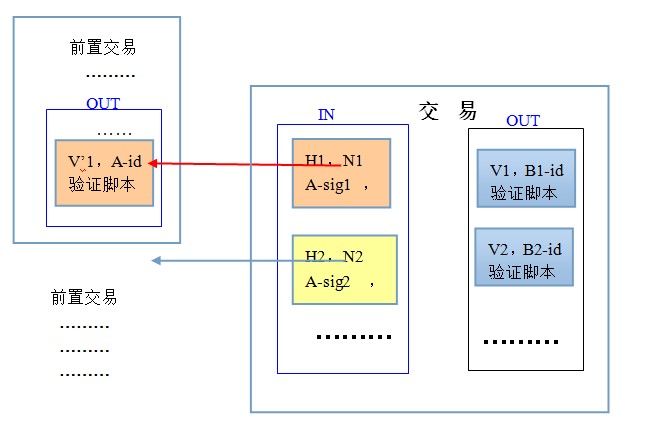
����1������IN�����OUT��Ϊ���飬�γɶ�Զ��ϵ;
����2������INÿ���H*��N*�����У�H*(ָ��)ָ����ǰ�ý��ף�N*(���)ָ����ǰ�ý���H*�еĵ�N*��OUT���H*��N*���Ͼ����˸�IN���Ӧ��ǰ��OUT���磬ͼ�к��߽�����ɫ����ϵ�����ˣ�ÿһ����ϵ������������ǰ���ļ��Ľű�;
����3��������Ӧ����������A��IN�и���Թ�H*��N*��Ӧ��ǰ��OUT��ΪA_id(������������A��);
����4������INÿ���A_sig*�� ��������������A��˽Կǩ�����ҹ�ԿΪ ��������ǩ���Ľ��A_sig*��һ����ԭ���ǣ�����ǩ��ʱ�����˶���������A�Ҫ���϶�Ӧ��ǰ��OUT(�ⲿ�ָ�����ͬ);
����5������INÿ���ǰ��������֤��ʽ������֤�����������������A����֤;
����6������OUTÿ���һ��V*�����Ǹ�B*_id�Ľ�OUT�����н��֮��Ϊ����ܽ�IN��ÿ���о�û����ʾ�г������Ľ���ǴӶ�Ӧ��ǰ��OUT�еõ���IN�����н��֮��Ϊ�����ܽ�
������Ͻ����Կ�����һϵ�еļ�����ɣ���ˣ�����Ͻ�����֤�������������棺һ�ǽ���Ȼ������ܽ��ܳ��������ܽ��;���ǽ��ĺ����ԣ���������һϵ��(��Ӧ��IN����)���ű�(�磬ͼʾ������ɫ�鹹�ɵ�һ�����ű�)��
����3.5 ������ϵ
�������ˣ����ǽ�������������(���ڱ��ر�)�˱���������ϵ��
����1����������ÿ��������ɽ���;
����2�����ף�ÿ�����װ�������������Ŀ(����IN)�����������Ŀ(����OUT);
����3��������Ŀ(IN)�������Ŀ(OUT)�����ǻ�����Ԫ�������ܶ������ڣ������ǽ�����ɲ��֡�
��������һ�ڿ���֪��������Ƿ��ڵ�������������ÿ��������Ŀ(IN)�������Ŀ(OUT)���н���������Ŀ(IN)�Ľ������ʽ������(����ǰ�õ������Ŀ(OUT)����)��ʾ��ͼ��
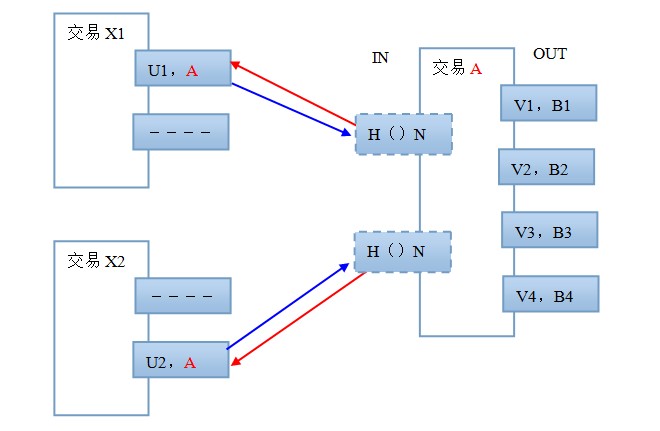
l �ͻ�A���Ľ���A�����ΪOUT�顢���ΪIN��
-
�����Ŀ(OUT)����������(����˭)���磬(U1��A)��(V1��B1)�ȵȡ�����һ����������������Ŀ�������е���š�
-
������Ŀ(IN)�У�H()N��ʾͨ��Hashֵ�ҵ���ǰ�ý��� ����ͨ��Nֵ( )�ҵ� ��OUT���еڸ�OUT����ЩOUT�о�˵���ʽ� ��A����Ϊ������ʾ��������Ŀ(IN)�н�����ʾ��д��������Ϊ��ͨ�������ҵ���Ӧ��OUT����OUT�еĽ��ǡ�
-
�����Կ����ʽ������ɢ���������IN�ռ��ʽ��ұ�OUTɢ���ʽ𣬼ٶ�û�������ѣ�����ߵ��ʽ�֮�͵����ұ��ʽ�֮��(�ǵ�������ǰ�潻��ʱ˵��ȫ��������ô)�����ǿ��������ģ���Ϊ������A�У�A��δ������ʽ�OUT���Լ����ɡ�
-
�ʽ�����������߱�ʾ��������ߵķ���պ��෴�����߱�ʾ�����ʽ�����������ͨ���������ɢ���Ǻ��Ѹ��ٵġ�
������һ�γ����˷����෴�ļ�ͷ�ߣ������岻ͬ(��Ҫ����)������ʵ������ָ�룬�ٶ�������������������ӵ�ǰ���ɻ�˷��һ������������(��������)�����������������������������ײ�����������ʱ�����˷�����ӣ�����������ݽ����������̻���(�磬����A�����ĺ�������������X1��X2���������������)��
������ͼ�У��ҽ�IN�ı߿����ߣ�������ֻ��������ǰij��OUT����Ӱ��������Ȼ��������ϵͳ�в�Ӧ��������Ӱ����
����˼���⣺��α�������Ӱ��(˫��֧��)?
������4 ��Ա����
����Ϊ�˸��õ��������������������ƣ�����������е�������������������˵ġ�
����4.1 �����ϸ�
���������Զ�������������һ����������������
����1�����������ɹ�Ա����Ա�ü�Ч���ʣ�����������������������һ��Э�����˾��ɳ�����;
����2��������һ�������׳������ͻ���ǰ���ڵķ�ʽ��ɽ���(�����ڿͻ����꽻��)�����������ŵ����׳��о�����(������δ���ˣ�ƽʱ˵���첽��ʽ)��ֻ�����ǽ�������ֽ�ʵģ������ɳ�����Ƶġ�����Ա�ɹ����Ϳ����ĵ��ӽ�����
����3���������������������˱������ɹ�Ա�����׳��еĽ�����(д��������)��
�������ǿ�����������������������
�������ȣ����ǿ�������μ��ˣ������������Ļ����ṹ���������е����ݿ���һ��÷�˶�����������װ�ܶ�����ף����ԣ������������ˣ������׳��еĽ�����װ��һ��÷�˶�����������һ���µ�����ͷ����������ͷ����ǰһ����ͷ��ָ�ƣ�������������һ�ڣ���ͼ��ɫ�ڣ��µ�����ͷ+��÷�˶���������������˽����������ˡ�

�����ڶ���˭������?������ͼ�п��Կ������¼�����(����)������(ͷ)�к���ǰһ����(ͷ)��ָ�ƣ�������������������һ��˳������Ӧ��һ�μ�һ��������һ�������(��������)����һ����Ա��ɡ���ô�������ˣ����ĸ���Ա����?����൱����һ�����������β���һ������ʱ�������������⡣��ʯͷ��������������ѡ�١��������Լ�PK�����ȶ�����������е�ѡ�����������趨�ij����£�PK��Ա����������(�����ܼ����)�Ǹ�������ѡ��������������п�ѡ�õĸ���֤��(��������֤�����磬������֤����Ȩ��֤�����ɷ���Ȩ֤��)��
�����Թ�����֤��Ϊ����Ϊ�˾������ĸ���Ա�е���ǰ�ļ��˹�Ա������(����)��һ���������⣬˭�����˭ʤ�������ڹ�Ա�ü�Ч���ʣ����ԣ��������ȥ���⣬���������������Ҫ�������ƽ�����ƴ�����������������������������ʽй�����֤����
��������������Ƶ�ȿ��ơ�����������ʷ����ÿ����һ���飬����һ��������(÷�˶�����Ҷ��ȫ�ǽ���)����Ȼ��ϣ����ʷ���������죬���Ը�һ��ʱ�䴰���������ٶ�(�磬10����)����10���Ӳ���һ�����飬��������ҪЭ������Ա��ʱ�ӣ��Ƚ����ѡ���������һ�����ǵ�����ʱ�䴰�ھͲ����ϸ���ƽ�������µ�ʱ�䴰�ڡ��ڹ�����֤��(���꽻��)�ij����£���������ѶȾͿ��Դ���һ��ʱ�䴰�ڣ�ʵ��ʱ��Ϊ��������Ǹ���Ա��ʱ�䡣�ڼ������м�һ�������ѶȵIJ������Ϳ���Э��ʱ�䴰�ںͼ�����֮��Ĺ�ϵ������Ƶ��Ҳ�ǹ�Ա�ľ���Ƶ�ȣ���������һ�μ�һ��������Ա��һ��һ��������
����4.2 ������֤��
�����Ͻ�����˵�������������Ĺ�Աͨ������������������ϸڣ�����һ��ʲô��������?
������������Ҫ��������ͷ��ָ�ƣ���������ü�����������ƣ�
����1������ͷ�м�һ������Nonce���������ÿȡ��һ��ֵ���ܵõ������һ��ָ�ƣ��Ըñ������ȡ����������(�����ƽ�)��һ�������ָ�ƺϺ���Ҫ����������Ϊ���������;
����2����������ָ�����ù�ϣ��������ϣ������һ���ܺõ����ʣ����Ǿ��з�ɢ����(ɢ��)��Ҳ����ָ�ƻ�Ͼ��ȵطֲ����ܷ�Χ�ڡ����ܷ�Χ����һ����ΪĿ�귶Χ��������Ҫ��������Ϊ����ֵ����Ŀ�귶Χ(�Ǻǣ�������ɱ�?)������Ŀ�귶Χ������λ���������ǻ�һ��˵����ǰ����ٸ�0��������һ���Ͻ�(��Ϊ��������ʾΪ16����Ϊ000��000FFF��FFF)��������������Ҫ��������Ϊ����ֵС���Ͻ磬��Bits��ʾ�Ͻ���0�ĸ���;
����3����Ȼ��BitsԽ��(�Ͻ���ǰ��0�ĸ���Խ��)����ķ�ΧԽС�������Խ��(����ɱ�)����֮�������Խ���ס��Ͻ�����˵��Ҫһ�����ѶȲ�������Bits���Ǹò�����������Ҫ��������(�磬����)��ȥ����������������������Ǹ�ʱ�������ô���������ת���ɺô��������������������ÿ2016������һ��(ÿ10���Ӳ���һ�飬���ܶ�Ӧ2016��)�����ڹ�ʽ�ԡ�
�������������Ļ����ṹ�У���������������ͷ�Ļ����ṹ����Ҫ��ȡ������֤��(POW: Proof of Work)��������ͷ����Ҫ�����������ֶΣ���ʱ����������ͷΪ��

��������˵�ı����ƽ⣬�Ƕ�Nonce�������ȡ�����㣺ȡ��һ��Nonce��������ͷ�Ͷ��ˣ��Ӷ�ָ�ƾͶ��ˣ��жϸ�ָ���Ƿ�����Ҫ�����������α���������������ģ���ʵ���Dz���ȫ���ǵ�ѭ�����У�������ȫ���ǣ���ˣ�����������forѭ��������Nonce��0��ʼ��һ���㣬ֱ��ָ�����뷶Χ�������⼴���ҷ��ϵ�Nonce��
������Ա���������������ô����ҵ�������һ��ô?�����һ�����⣬���ƴ����forѭ�����㣬�Ǹ�����������ǿ�Ĺ�Ա��Ա��ʤ�������ľ�����û������(ÿ�ζ�����)��
�������ڻ���һ�����أ�MerkleRoot�����ڽ�����÷�˶���Ҷ�ϵ�����ֻҪ�ڽ����״ӽ��׳�����÷�˶���ʱ����������ԣ��Ϳ��Ա�֤MerkleRoot��һ�����Ӷ�����Ա��ͷ������ͷ�Ͳ�һ����������˹�Ա�����������ɷݣ�����MerkleRoot���������ڶ���Ŀ�ij�ǩ���ڡ����⣬��������һ��������й�Ա���кܴ�����ɶ����֡�
�������������ƽ���̳�Ϊ���ڿ�������Ӧ�أ���Ա��Ϊ��������Hash�ĵ�5�����ã���Ϊɢ�к������������ڿ�����
����4.3 �����Ͻ���������������
������ǰ�����������������ᵽ�����������?
�������ȣ��ᵽ���Ϻ�Ҫ��������������Ҫ����Աû����������(����䵱���ܣ�Э���������)��Ҳ����Ҫ����ȥ����������
������Σ��ᵽ���Ϻ�Ҫ��������������Ҫ�����й�Ա�ܹ������˱���(������)�ͽ��׳ء�
������������������������ȷ�����պ�P2P(peer to peer)�����������ⷽ���Ҫ��P2P�������Dz���İ��(�����һ����Щ�����ҹ�����������)����ʵ������Ӧ�ò������(����)���磬װ������¿�����û��γ�һ����������������P2P����������Ƶ��������������ˣ����ǿ�����������¿����ͬ�IJ������һ�����������������������������������㲥����ѯ�����أ�ÿ����ڵ���Ϊһ��Ա���������γ���������Ҫ��������������(��������)���б��ϵ����ľ��ǡ����رң�һ�ֵ�Ե�ĵ����ֽ�ϵͳ�������������Ե�������P2P����
��������������Ĺ�Ա�ֲ���ȫ����(����P2P�������ʿ�������Ϊ��һ������������)����Ա����������г�Ϊ�ڵ㣬���в�ͬ����������ǰ���ڵķ�ʽ���ͻ����׳��ύ���ף���Ա(�ڵ�)�����������顢�����������ˣ�ÿ����Ա(�ڵ�)����ȫ�����ݡ�
�����ᵽ���Ϻ�����ϵͳ������������Э���°�ǰ��ԭ����������Ȼ������һ����ȥ���Ļ�����ϵͳ��Ҳ��һ���������ķֲ�ʽ��ϵͳ������һ�����ݴ���������ϵͳ��
�����ܽ�һ�£����������ŵ�P2P�ϣ�1���������������в��ɴ۸���;2��P2P�ֱ�֤�����ݲ��ᶪʧ;3��P2Pʵ�������ݵĹ�����������Ҫ����ά��(Ҳ������)������Ҫ�ֱ���ʵ�����˱������ȡ�����������P2P���ߵĽ�ϣ��γ��˳�ǿ�ķֲ�ʽ���ݿ⡣
�����Թ�Ա(�ڵ�)Ҫ��ɷ��ɣ����������ۻ������¼��裺
�����ڿ������ֵ����(Hash)������ʹ�ù�Ա��1)Ͷ����������CPU��GPU(ͼ�δ������ʺ��ڼ���)���ٵ�ר�ŵ��ڿ����2)�ı���ԣ�������������Ͽ����в����ڿ�ÿ�����̳а���ͬ�������������磬��ͬ�Ľ������С���ͬ��forѭ���Σ��׳ƿ����������
��������ʹ������Ͷ�벻������������Ҫ��֤10��������һ���Ƶ�ȣ��ʣ�ֻ�в��ϵ����Ѷ�ϵ����ʹ�ѶȲ��ϼӴ������ǣ�
����1��������̫�ѣ�һ�������Ŀ�������ͼ�����´���С���˳�������Խ��Խ���е������Ĺ�Ա���У�����������������ͷ��;
����2������������Ͷ�뵽�����ü�ֵ����������У�����Դ�����˼�����˷ѣ����Ǵ�Ҷ�POWڸ���ĵط�;
����3���Ѷȼ�ǿ������ָ�Ʒ�Χѹ������ײ�����������������ƣ�����˫ָ������ָ��1=Hash(����ͷ(��Nonce))��ָ��2=Hash(����ͷ(����Nonce))��ȡָ��=Hash(ָ��1 || ָ��2)��
����5 ���չ�ʶ
������Ա��������ͻ��Ȼ�������˵ij�ͻ�������Ҫһ�����ƣ�ʹ�ü��˽������������һ��������
����5.1 ��������
�����ڹ������У���Ҫ��һ�ֻ���������Ա���ˣ��Ա��ر�Ϊ������Ա���ڿ���(������)��ʤ�����ò���һ����(��������)��Ȩ������������P2P�㲥�����������飬��������������Ч������������ױ����ˣ���������ý��������رҵĽ�����Ϊ�����֣�
����1�������ѣ����佻�ṹ������֪��ÿ��������һ��IN��һ��OUT����ÿ��OUT�ж����˸���������OUT�ĸ������֮��Ϊ�ܸ������;��ÿ��IN�ж�����������(�����Զ���ģ��������Ӧ����Դ��OUT)������IN��������֮��Ϊ��������ܸ������������������ֵΪ�ý��������ѡ��������������ˣ��ʹ�Ա��ø�����������֮�͡�
����2������(�䵱���ҷ��й��ܣ��磬���ر�)����ÿ����һ���飬����һ����ң�Ϊ�˱��ⷢ�й��������رҲ�ȡ�Ŀ��Ʋ���Ϊ��ÿ4�꽱����룬һ������ֹͣ���С�
�������������ֵĽ�����������ǰ�������У�1�������ѣ����ڹ�Ա�Ǿ������˵ģ����ԣ��ͻ�A������Aʱ������֪����˭���ˣ������������ڽ���A��OUT��ָ�������˹�Ա;2�������ⲿ���ʽ�û�ж�Ӧ��IN�Ϊ�ˣ�ÿ�������ж���һ�����⽻��(�һ�����)��
 ���� ����
- �ý���ֻ��һ��IN��һ��OUT
- OUT��������������(V1)�ͽ���(V2)���ü��˹�Ա�Լ�(�磬��ַΪMy)
- IN��ǰ�ý���ָ��Ϊ0(��û��ǰ�ý���)��IN�е�ԭǩ�����ִ�ʱû��Ҫ���ʿ��Ÿ���Ա����ʹ�ã��γ�coinbase��
������Ա������Ŀ�ĵ�ʹ��coinbase�ֶΣ����磬��ɷ�һ�������ı�ֽ��Ƭ�������ÿ���γ�ʱ�������������ñ�ֽ�ϵ�ʱ�䡣
�������⣬�����������ڷ������С���������������������ͬ����������ǰ�趨(�ͻ��ύ����ʱ�趨������Ա�����ں�)����ˣ���ԱΪ�������棬������ǣ������Ѷ�Ľ������ȼ���(��������)�������������Ƶ�ʹ̶������������������ޣ����ʹ��Щ��������(����)�Ľ������ڼ��ˣ������������ڣ�����Ʊ�ٵ��˳˲��ϳ�һ����ͨ�����趨һ��ʱ�䴰���ڣ�δ���˵����ϻ���������������
����5.2 ��������
��������������������������������������ڿ�ʵ������ΪӲʵ������ʵ����Ӳʵ������Ͷ����������͵�������ʵ����Ҫ�ǿ�������������������Ч����(�磬�����Կ�����������Hash)������ר��оƬ���㷨�Ż��ȡ�
�������ǿ�������㷨�Ż���
�����Ͻ�˵����Ա�����⽻��(�һ�����)���ڸ��Լ����ձ��꣬�ý�������һ���ֶο����ɹ�Ա����ʹ�ã��γ�coinbase�����ڴˣ����ǿ���������ƿ�ء�
�������Ӷ�coinbase�ж���һ�����ֶ�coinbase_nonce(��������)��������ͷ��Nonce���ƣ������ڿ�coinbase_nonce�仯ʹ�øý��ױ仯������÷�˶����Ĵ�������仯���Ӷ���������ͷ�仯��ǰ�棬����˵��ͨ���ı佻������������÷�˶����Ĵ�������仯�������������ʹ����÷�˶������ڵ㶼Ҫ���㣬��coinbase_nonce�仯������÷�˶����дӸñһ�����ͨ������ͨ����;�ڵ���Ҫ���㣬�ʿɵ����������ڿ���coinbase_nonce�仯ȡ�������������������ڿ�ͳ���coinbase_nonce�仯��Nonce�仯��˫��ѭ���������൱���������������ϰ�װ����������������ť�����ϵ���������������������һ����������������ͳ��˺ϸ�������飬�Ϳ���P2P�����ύ�����顣˫��ѭ��ʾ����
����For( 0<coinbase_nonce<M;coinbase_nonce++){ //��ѭ��
���� For(nonce=0; nonce<N;nonce++){ //��ѭ��
���� ��������function(����ͷ);//�����仯����ӳ������ͷ��
���� If(���ڷ�Χ��)return true;
���� } //��ѭ��
���� } //��ѭ��
����Ϊ�˺�������ǿ�����������������ѭ��(coinbase_nonce�仯)�ֶβ�֣��γɲ��й���ģʽ(�����ͬʱ�ڿ�)���磬��coinbase_nonce�仯��Χ[0��M]��Ϊ���ɶΣ���i��[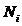 �� ��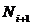 ]�ɵ�i���������㣬������i�����̵���������εĵ�һ���Ϊ�� ]�ɵ�i���������㣬������i�����̵���������εĵ�һ���Ϊ��

������n�����̼ȿ�����һ����Ա(����ڵ�)���У�Ҳ���Է�������ɹ�Ա�ڵ��ͷ���У�����Ǻ��ߣ�����Ҫ���һ�����������ƣ��Զ��������佻��(����)��
����һ��������һ���ϸ��������(ij�����̲����Ļ������о������ֲ�����)�����ؽ���������ֹ��ǰ���ڽ��еĸ��ڿ���̣�������������Ϊ����������һ���ڿ�����ǿ���ڿ���
����5.3 ����?PK����ʶ
������Ա���ڿ��������У����������͵������?�ش��Dz��ܣ���Ϊ��һ�¸��������(����ͷ)�к�������ǰ������ָ�ƣ���������ǰ������û���γ�ʱ��û�취��ʼ��һ����������(�ڿ�)���䲻����͵��������������ǰ������(�磬��ǰ����÷�˶���)��һ���յ�����ǰ�����Ĺ㲥������ȷ���Ƿ��Ͽ��������Ͽ�������ָ�㽫����Ϊ����(��������ָ��Ƕ�������������)������һ������⡣
������������P2P���Ͻ��У�������ڼ��������ʱ���ڣ��յ���A��B��C�㲥������ǰ���������յ��Ĵ���ΪA��B��C����ʵ�����ɴ��������յ��Ĵ���ΪB��C��A��˭Ҳ����˭��������������(�ֲ�)��
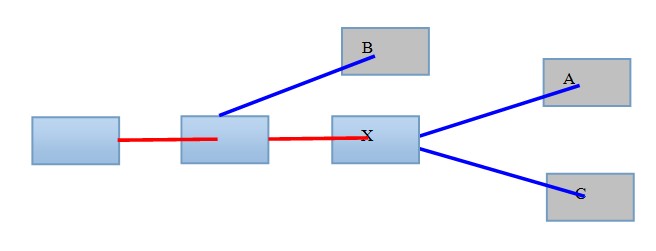
������ʱ���������Ͽ���A��B��C����һ��?�����Ҫ����һ�����Ͽ����Ĺ���Ȼ����������ȷ��ǰ����(�������ϸ������齫������)���������£�
-
��һ����Ȩ(����)����ʹ�����������������������Ȩ����Ȼ������ͼ��B������;
-
�ڶ�����Ȩ(��������)�������϶ཻ����������;
-
��������Ȩ(�����ʱ��)��������ʱ���Խ��Խ���ȣ���ʱ����ǹ�Ա(�ڵ�)�����(��Ҫ����)�����ԣ�ֻ��ʱ����Ϻ�һ����Ҫ����Ǻϸ�����顣
����һ����ѡ��������ǰ����(�磬C)���㽫����Ϊ�����Ͻ�����һ��Ĺ��죬��ʱ����Ŀ�е�ǰ���Ͽ�����������Ϊ��
����ÿ����Ա����һ����Ŀ������ǰ�Ͽ�������������֮����˵����ǰ������Ϊ���ڳ�������ԭ��ʹ����������������������磬C֦����û������A֦(C����֦)���ɹ�Ա(�ٶ���Ա�������ع����)������ѭ���������γɣ������������������������PK�����ɳ�����һ�����������൱�ڹ�Ա���������ͶƱ(�磬�����������CͶ��һƱ)������������ĻҶȱ�ʾͶƱ�Ķ���(��ɹ�ʶ�ij̶�)��������������ɫ��ұ�ɫdz��(��Ϊ��ʶ��)��
�������������еij������Ⱥͽ�������(���������¶��н���)�������˹�Ա����ָ��˼����������ʹ��Ա��ʱ�����Լ��Ĵ���ѡ����ˣ���ʶ���ϵķֲ�ֻ�����ڹ�Ա��û�з����Լ�����ʱ�������ִ���ֻ�Ǹ�ʱ�����⣬�ʹ�ʶ���ϵķֲ�ֻ���������ұ��飬�����������ڼ��١�һ������(���ر���Ϊ6��)��ֲ�ĸ���Ϊ0����Ϊȫ����Ա�����Ͽ���(������˹�ʶ)������ǹ�ʶ���ƣ����澺����������ɳ����ɹ�ʶ��
������6 ������Ϣ���Ի�
����ǰ������˵��������������ʷ��������ʷ��Ϣ���������������Ĺ��ɡ�
����6.1 ����������Ҫ��?
����ǰ�����ǵ�������ͼʾ�У������������ģ���������Ϣ�����������ģ�ʹ�úܲ�����ģ����磬��������������Ҫ�ҳ���ķ�֧(�������������Ⱦ��Ǹ߶�)�����Ҫ�������(����֧)��ÿ������ĸ߶ȣ�������ĸ߶������Dz������������е�����������Ϣ(�ɴ��������ṹ���Ƶ�����)����Ч�ʽǶ�������Ӧ����Щ����������Ϣ���Ի������洢�����Ա����ø���Ϣ(����ÿ��ȥ�Ƶ�)��
�������������������Ϣ(�磬�߶�)Ϊ����˵�����ı�Ҫ��
�������Ͻ��У��ٶ�������ǰ��֪(�豣������)����X�ĸ߶�Ϊ100�������������Ϣ�ó���������A��C�ĸ߶�Ϊ101���������νǶȽ�������ڵ㲻����ܱ������ڵ��Ƶ�������Ϣ������������������Ƶ�������X�ĸ߶�Ϊ100������ʹ������仰��
�������Եİ취�ǣ�����ڵ㽨�����õı�����������Ϣ��������������Ҫ��������(��)�н�������Ϣ���Ի������뱾�����ݿ��С���������(��)������������Ϣ��������֮�����ɣ����ǿ�����Ҫ��
�����������һ���¼���Ĺ�Ա(����ڵ�)����Ӧ��ֻ�������飬����ĵ�һ�������������ϵ����飬���ݴ˽����Լ�����������Ϣ�������������������ǿ��Զ������һ��������
����������(ͷ)��ָ����ΪKey��������ΪValue������(Key��Value)����(Key��Ϊ����)�����ڿ���������ֱ�Ӽ����Key����Ͱ���������װ��һ�����У��Ըñ�����һ��(ǰ������ļ�(ָ��))��preKey,���ǰ���������(ͷ)Value�У�����ȡ������������ת���������blocktab��(Key��Value��preKey)���ٶԸñ�����һ�У����������еĸ߶�High,��ʱblocktab��(Key��Value��preKey��High)�����˱����ǿ��Ƶ���High�е�ֵ��
������ʼ���贴���Ϳ�(Key��Value��if(preKey==0)����High=1);
����for(�α�(Select * from blocktab when High=null)){
���� �赱ǰ�α��¼Ϊ(Key_X��Value_X��preKey_X��High_X);
���� Update �α�ָ���ļ�¼ set High_X=(Select High from blocktab when Key =preKey_X)+1;//Ϊǰ������ĸ߶ȼ�1 }
������ķ�֧�ĸ߶Ⱦ������ij��ȣ�
���� Select max(High) from blocktab
�������ݹ�ʶ���ƣ�����̭��֧�ü���������ɾ��(����ɾ��)��
����������������Ϣ�����ù�Ա�յ��µ�����Ϳ��Ժܷ����(�����Ǵ�ͷ����)�õ�����High���磬��������Ϊnew����ȡ����������伴��(���α�ָ���ļ�¼��Ϊ�����顢*_XΪ*_new)��
�����´�����Խ���˫���ݱ���(Key��Value��preKey��postKey)
������֮�����ڲ�ѯ(�Լ�����ʱ�IJ�ѯ)������������Ϣ�����DZ�Ҫ�ġ�
�����������У�����Ա�˳������Լ����Ѿ����ڵ��������ݿ���Ϊ��������������Ϣ���������������ϴ�������������Ӧ�õ�Ч��(���ѯ���)�������Խ���Ը���������ѵ���Ϣ�ŵ���������Ϣ�����У������ŵ��������С�
����˼���⣺Ϊ�β������������е����߶���д������ͷ��?
����6.2 ����˫��֧��(1)
����˫��֧����ָA�������ʽ���(ͬʱ����ͬʱ��)��һ�������ʽ�ת��B����һ�������ֽ�ͬһ���ʽ�ת��C��
��������ǰ������������Ϣ�������Ϳ���������ͨ����ѯ���ж�һ�������Dz���˫��֧�����Ӷ�����˫��֧��(��ȻҲ�����˶���֧��)��
����Ϊ�������⣬�����ȼٶ����н����Ǽ��ͱһ�����(������ֻ��һ��IN��һ��OUT���һ�����IN����ǰ�ý���)�������ּ����£�����IN(ָ��)ָ��ǰ�ý���(��OUT)�������ȥֱ��һ���һ����ף�����������ҵ���һ��������������������ɽ�ÿһ�����鵽ij�������������У��Ǻǣ��������е����н����ó������ͱ�������һ�������������������������(����������������������)����������������������������(�һ�����)����ָ����ǰ��������ָ��(IN��ǰ�ý���H())��
�������������������������������ƣ�˫��֧��ʵ�����ǽ������ķֲ�(һ��ǰ�ý��ֳ���������������)��������������δ����ֲ�ģ���Ա��ְ�����Լ���֤�Լ����ã���ÿ����Ա�Լ���������������һ����(���ֲ�)���������Ա������������һ��ʱ�������ͬ(�����Ϳ�)��ͨ����ʶ�㷨��֦,�γ�����������������������(��ֻ�����Ķ��˴��ڷֲ�)��
������ô��δ����������ֲ�?(1)����������ͬ����Ա��ְ�����Լ��������Լ���������֤�Լ����������������ֲ档���������˵Ľ���һ����һ�������У�һ������һ���DZ�һ����Ա���뵽�������У���ˣ���Ա�����α�֤�������Ͽɵ���������(�����¼��ϵ�����)���������������������ڷֲ档(2)������������ͬ�����еĹ�Ա�����������������һ�𣬿��ܳ��ֲַ档��Ȼ�������������ķֲ������ڹ�Աѡ��ͬ����������֦�����µġ������ǿ������������������������ϣ������������������������й�Ա���Ͽɵģ������������������ɵIJ����Dz���ֲ�ģ�Ҳ����˵�����������ķֲ�����������������ļ�֦����������
�����ͻ���Ȼϣ��˫��֧��(һ��Ǯʹ�������������)�����ԣ��ͻ��������˫��֧���Ľ��������Ǿ�Ӧ�ɹ�Ա���˵�ʱ��Ѻùأ����ͻ��������Ա��ͬһ����(���ı)����ˣ�������������ǰ�ļ��裺�ع�صĹ�Ա������Ӧ����50%�����ڲ����εĻ�����Ҫ���㹻������������
����ǰ��˵���ع�ع�Ա��ְ�𣺱�֤�Լ����������������ֲ棬������Ӧ��ô��?�ڼ���(�ڿ�)ʱ��
- �������ˣ�һ�����յ��������к���˫��֧�����ף��������Ͽ���������(��Ϊ�����鲻��ȷ�����ڸ�����������ڿ�);
- �����Լ�������˫��֧����������������;
����Ҫ�����������㣬�������һ�����˫��֧���ķ�����
������һ������ͨ������������������Ϣ�����ķ�����������������ϸ��ڵ�ĸ߶ȡ�����������������������������ԣ��Ա���ƣ�
�����������ı�blocktab��(Key��Value��preKey��High)
�����������ı�tran_tab��(T_Key��T_Value��T_preKey��Flag)
�����ֶ�˵����
- ��T_Key��������ָ�Ƽ�H()����Ϊ��ֵ
- ��T_Value��������
- T_preKey����ǰ�ý������ļ�ֵ(��ָ�룬��IN��ȡ��)
- ��Flag����־�������Ƿ��к������ף�1Ϊ�У�0Ϊ��
��������������������High��ֵ�����ԶԽ���������Flag��ֵ�����״������γɺ��ù�Ա�յ�һ���½��ף�������ͨ���ý���IN(ָ��)�ڽ��ױ����ҵ���ǰ�ý��ף������ǰ�ý���Flag=1(�����к��ý��ף���ʾ��֧��)������Ϊ����½�����˫��֧����ֱ������(�������ֲ�)���������Ͽɸ��½��ף�����������һ��(�½��׳䵱�˸ý����������ҽ��ף���ʱ��(1)�½��ײ�����У���Flag=0;(2)����ǰ�ý���Flag��Ϊ1����ʾ��ʱ��֧��)�����յ�һ�����飬���൱���յ������������н��ף�����������������״�����ͨ��Flag�����飬�Ӷ�������˫��֧����
��������ش��Ͻڵ�˼���⣺Ϊ�β������������е����߶���д������ͷ��?
����1���ٶ�������ͷ����һ���ֶ����߶��������յ��˸����飬������д����߶�ô?���ܣ��������Ƿ��۸ĵġ�
����2��������ֶ�ֻ�����������ʱ��д��������������(�߶�)�������ľ�������Ա���鱨���߶��������ɣ����ԣ�Ҳ�����ɹ�Ա�ڲ�������ʱ�
����3����ʹ����ͷ�������߶����ֶ����ܱ�֤������ȷ�ԣ���ѯ����Ҳ�����㣬������Ϣװ�����ݿ⣬�������ݿ�ļ������ܾͷ����ˣ�����ͼ����е����б�ţ�������Ҫ��һ��ͼ�����ϵͳ����ˣ����������е����߶�����������֤��������ʽ�����������С�
����ͬ�������ɣ����Խ��������⣺Ϊʲô��֧���ı�־Flag��ֱ��д�ڽ����ϣ���Ҫ����������Ϣ��?
����6.3 ����˫��֧��(2)
���������������ڼٶ����н����Ǽ��ͱһ������������Ƶģ���ȡ����һ����ʱ������Ϊ��Ͻ���(��������һ��IN��һ��OUT�����ͱһ�������Ϊ������)��ͨ����ȵ��ַ����ǾͿ��Խ���Ԥ��˫��֧���ķ�����
���������ӵ��ϣ���������������ȣ�����ʱ�������������ĵ�һ����ǰ�ý��������������е�ָ����ָ����ǰ�ý�����;����Ͻ���ʱ��������һ��IN�����ĵ�һ����ǰ�ý���һ��OUT����������һ��IN�е�ָ��(ǰ�ý���ָ��+ǰ�ý�����OUT���)��ָ����ǰ�ý���һ��OUT�����ݴ����ǿ��������ƣ�
����1������ʱ���Dz���ǰ�ý������������Խ���Ϊ��¼;����Ͻ���ʱ���Dz���ǰ�ý���һ��OUT���������ǵı�����������һ��OUT��Ϊ��¼��λ(�����е�һ�б�ʾһ��OUT);
����2������ʱ���Dz�(ǰ��)���ף��ʼ�¼�Ա�����ָ��(ָ��)Ϊ��;����Ͻ���ʱ���Dz�(ǰ��)������һ��OUT���������ǵı���������һ��OUT���ļ�Ϊ��������ָ��+��OUT�ı�š�
����3������ʱ����ǰ�����Ƕ�Ӧ����һ��ǰ�ý�������һ��T_preKey������Ͻ���ʱ����ǰ�����Ƕ�Ӧ��������OUT��(Դ�ڲ�ͬ��ǰ�ý���)�������preHash || N*��
��������ʱ��tran_tab(T_Key��T_Value��T_preKey��Flag)
������Ͻ���ʱ����ǰ���취������һ����OUT������
����OUT_tab(Hash || M��T_Value��preHash || N1��preHash || N2������Flag)
����OUT_tab�и��ֶε�˵����
- ��Hash || N����¼�ļ�(����ָ��Hash+��OUT���M);
- ��T_Value����OUT���ڵĽ���
- ��preHash||N1��preHash||N2����������OUT���ڽ�������INָ�룬(�����Ƕ�̬�ģ����趨һ�����ֵ);
- ��Flag����OUT�Ƿ�ʹ��(���Ƿ���һ��INָ����ָ��)�����У����Ǹü�¼��FlagΪ1;
�������˴�������OUT_tab����Ա����һ���½��ף��Ը��½�������IN����ѯ��Ӧ��ǰ��OUT������һ��ǰ��OUT��¼��FlagΪ1����ܾ��ý��ף������Ͽɸý��ף���ʱ��(1)���½�������IN(����)ָ�����OUT����¼��Flag��Ϊ1(��ʾ��������);(2)���½�������OUT(����)������OUT�����У���Flag��Ϊ0��
��������һ������ɷ��ڽ��ĺϷ������ų����½�����������INָ��ͬһ��ǰ��OUT����Ҫ����IN����ָ�벻�ظ����ɡ�
������7 ��ظ�ϵ��
�������´���������ߵĽǶ������۲�һ��������������
����7.1 ��Ա(�ع��PK���ع��)
�������ع�ع�Ա�෴�������ڲ��ع�ع�Ա���������ࣺ
����1������Ϊ�ģ���ֻ���Լ��ڿ�ȥ�����յ�������ͽ��ĺ�����(�Ӷ���ʡ�˴�������ȥ������)�������Թ�ʶ�����ס�
����2�������ߣ���Ϊij�����棬α�졢�۸Ľ�������˫��֧�����ף�����Щ����װ�������У���ϣ��ͨ����ʶ�㷨�������������������С������������ع�صĹ�Ա����������50%����ǰ��(�ϸ����ع�صĹ�Ա���ڹ�ʶ���㷨���������ߵ�)�������ߵ�����һ���ᱻ��֦��
������Ȼ���ع�ع�Ա��ΪҪ��֤������ȷ�ԣ�������Ҫ��������֤����(���ع�س�û��Ҫȥ��֤)���ܽ�һ���ع�ع�Ա�Ĺ�����
����1������ά����ͬ������ͽ���(�����γɱ��ص��������ͽ��׳�)��������ά�����صĸ�����Ϣ��;
����2����֤�����������������У���֤�յ�������ͽ��ף�������ͽ����Ƿ��ǰ�������ɵ�?�Ƿ���˫��֧��?������֤������뱾�صĸ�����(���ⷴ����֤������������֤����)��ͨ���ø������������ʽ������֤���磬ǰ��������˫��֧�����鷽ʽ����Ա��֤��
- ���½����ڲ���ͻ;
- ���½����������Ͽɵ������еĽ��ײ���ͻ;
- �������������н����������Ͽɵ������еĽ��ײ���ͻ;
����3����ƣ���������֤�����Լ����������н�����֤�ű�;
����4�����빲ʶ����ͨ������֤�����飬����ʶ�����ȼ�����Ա���Ͽ�������(������Ϊ���������Լ�������);
����5�����뾺����ѡ��ϸ�Ľ��ף��������Ͽɵ�����Ļ�����(������ָ��)�����Լ������飬�������⣬һ������㲥������;
����6�����̹߳������磬ǰ���Ŀ��ģʽ���е��߳�Ҳ��ǿ��ϵ���磬ͬ���̷߳��ֱ���Ҳ����������⣬Ӧ֪ͨ�����̣߳���ʱ��ֹ��������ļ��㣬�������¼����⡣
�����㷨��û�гͷ������ߣ����ǽ����ع���ߡ��ڼ��������£����������������Ϊ����������ﲻ�ɹ�ʶ��������ͼ�����ԣ��ڼ����ͼ�����˫�������£������߱��а���
�����ӱ��رҵıһ������У����ǿ�֪�佱����Ϊ�±ҷ��к������ѣ������е�����һ��(��һ��ʱ���ֹͣ����)����ֹͣ���к�ֻ�������ѽ�����������ʹ�ù�ԱͶ������������������ɱ����������ɱ��������Ѳ�����Ļ����ᵼ�¹�Ա������Ͷ�����Ա(P2P�ڵ�)���ģ�˳�������P2P��ή������������̱��;�ɱ���Ҫ������������Ļ����������ֻ��������ͻ������̡���������������ֻ����ͨ�����������ѵ���ֵδ�䣬����ֵ(����)������ͨ���������������ģ���֮�������������ͨ�ǡ��ؼ������ǹ����ϲ������ͨ����ͨ�ǣ����ڵ�����Ӱ����ҵļ�ֵ������Ӱ�������ѵļ�ֵ���ٽ���Ӱ���Ա�����棬�Ӷ����¹�Ա������˳���P2P�����������̬�����У��п��ܴ������ع�صĹ�Ա����������50%����ǰ����������ʱ�����߿��ܻ����Լ��ķǷ�Ŀ�ġ�
����7.2 �ͻ�(�����ˣ�������)
�����ͻ�(������)ʵ�������������ߣ�����λ�ȡ�������ķ���?�����¼��ַ�ʽ��ѡ��
����1����Ϊ��(P2P��ȫ���ܽڵ�����֤�ڵ�)�������ڸ���������P2P���ϼ���Ϊ�ͻ�����Ϊ��Ա;
����2����Ϊ�����ͻ�(P2P�Ϸ���֤�ڵ㣬���ڵ�)�����ڸ���������P2P������Ϊһ����С���ܵĽڵ㣬�������Ա�Ĺ�����ֻ�������ף��ұ������ص�����ֻ��ͻ��Լ����(�׳ƣ�Ǯ��)���磬������������ͷ�ͺ��ͻ��Լ����ݵ�����ȱ��÷����;
����3��ͨ������������ȡ�������ķ�����������㣺(1)������Ϊ�������Ŀͻ�����������ʽ����;(2)�����Ŀͻ�ʹ�ó���ķ�ʽ(�磬�û�������)�ڴ���ƽ̨��ע�ᣬ��ֻ�����ƽ̨���н�������Ȼ���������δ���(�еĴ�������������)������ʵ���ǽ���ƽ̨�������ģ��磬���رҽ���ƽ̨��
�����Թ��������ԣ�������ʱ˵�������ܱ�����������ʱ��˵�������кܺõ���˽��������������ô����?
����1������֪�������û���֤��ϵͳ���ڿ���ʱ����Ҫ�ͻ�(����)�����˻����������뽫���߹�����Ҳ�����пͻ����˻�����������������������Ҫ���䱣�棬�Ա�˶ԣ���������������ϵ�Ŀ�����һ������ڱ�й©�ķ��գ���һ����ʹ��ϵͳ֪����˭(�ͻ�)����ʲô(���ƻ���˽��)�����������У�ʹ�ù�Կ��ַ��Ϊ�˻�������˽Կ�����ͻ�(����)�����룬����ʹ��(�ͻ����˻�������)��Ԫ�飬�����(��Կ��˽Կ)��Ԫ�飬������˽Կ���߱����־��������ϵ(����ѧ����)������Ҫ����Ӧ��ϵ����������ϵͳ(1)������ͻ���ʵ���ݡ�(2)������ͻ�������(˽Կ)�����ǽ������Խ����ͻ��Լ�(������˽Կ)���Ӷ��ܺõر����˿ͻ�����˽;
����2������Կ��ַ(�˻�)�ͽ�����ȫ���ɼ��ģ�������ǿɸ��ٵģ�ǰ���Ľ������ͷ�ӳ����һ���档����ֻ�Ǹ��ٵ��˻����棬��û�и��ٵ��ͻ����档��ʱ���ͻ����˻��Ķ�Ӧ��ϵ����Ҫ�������磬������֯���˻�����ʹ�ù����������������
����3����Ȼ�����������Ϸ������Բ²�ͻ����磬�����ֻ����˽��ף�ͨ���ֻ�ʵ����λ��ȷ���ͻ����Ӷ�������ϵ(��Կ���ͻ�)�����⣬һ���ͻ������ж������˽Կ�ԣ�ʹ��ǰ�������Ĺ�ϵ���������ں�������������Ϊ�������һ����Կ��������������һ����
������֮����������ͨ�������ֶ�ͳһ������˽���������������Σ����ݲ����ܺ��ù�Կ��ַ(��Ҷ��ɸ���)��˽Կǩ��(������ʵ)��ָ��(���۸�)�����û��ѹ�(������˽)��
������Ȼ������ͻ�ͨ������������ʽ��������������ô�ͻ������������Ľ�������һ�������û���֤��ϵͳ�����Ӷ��ƻ��˹������Կͻ���˽�ı�����
����˽����ʹ�ý��ڽ���Ӧ��ʵ��������������(�������)�����DZ��ر��ߺ��ԭ��(�������ں��к�Υ������)��ͬʱ��Ҳ�DZ�������ס��ԭ���������ԣ���������ͬ�����������ƻ����ơ�
�������ǵ������Լ�����ɲ�ȡ���Է���������˽������ҵ��ʹ�����뿪�����ķֲ�ʽ�˱�������ʹ�������������������û���֤����ϵ�����û���֤�����������Ļ�(�������������ڵ�֮���һ����֤����)��Ҳ�����Ƿֲ�ʽ(���˹����Լ����û�)����������������ʵ������KYC��(֪����Ŀͻ�)���������Ҫ��λ���������Ĺܿ��DZ���ģ��磺����Ƿ����ס���ϴǮ�Լ���غ����������ȡ�
����7.3 �ͻ�(�տ��ˣ�������)
��������������Ϊ���������տ��˺�ʱ���������ա�
��������ͻ�(������)A�Ǹ������ߣ�����������˫�ؽ���(�������ύ�ɹ�����δ���ˡ��轻��1�ͽ���2ΪA��˫�ؽ���)�������ɹ�Ա��������������У��ع�صĹ�Ա�ڴ��ʱ��֤���Լ������������Ҫ��
����1��ͬһ��������˫��֧�����⣺����������1�ͽ���2������ͬһ�����У�����������ֻ��������֮һ����Ա���Ͽ������ع�صĹ�Ա���Զ����ر�֤���Լ�����������ȷ���������?�磬�й�Աѡ����1����(��������1��)�����й�Աѡ����2����(��������2��)��������ͻ�����ܻ�λ�ڲ�ͬ�������С�
����2���������˫��֧�����⣺����������1�ͽ���2������һ������ʱ����������ֻ�������е�һ�鱻��Ա���Ͽ������ٶ���������1������2�����㲥��������1������2�����IJ�ͬ��������(����Υ�������Ҫ��)������ǰ��Ĺ�ʶ���Ƶļ�֦��һ��ʱ��(T)����1�ͽ���2ֻ��һ���������������������������������У���һ����Ϊ������������(���ڱ���֦����������������)��
�����������������а������ࣺһ�ǽ��ױ������ϸ��ǽ��ױ����ϸ��ھ�����ʧȥ���ʸ�(�磬�������)����������������������Ҳ����Ҫ���ǵ�(������������)�������ϣ������趨ʱ������(�磬һ��)�������ķ���ʱ�䳬����������ޣ�����Ϊ�������������ˣ���Ա�����������ڱ���ɾ���������⣬��������������Ͳ��������Ƶ�����ƣ��ڽ����ڣ����д�������ѹ������ɴ������������������������������ܼ��ˡ�
�����ٶ��ͻ�(������)A���ʽ�ת��B��Ϊ�˴�B����������飬�ͻ�A���꽻��1��֪ͨB����B���͵����飬�ͻ�(�տ���)B����������?����1��ת���B�ģ�����˫��֧���У�һ������1���뽻��2����ʱʧ�ܣ�������Ϊ����������������B��Զ�ղ�������1�Ŀ�����������ʧ��
�������ԣ�B��Ӧ��������������Ӧ�ȵ����㹻ʱ������ŷ�����������ʱ�������������Ĺ�ϵ�����ǿɶ��������ױ�ȷ�ϵĴ�����Ϊ�ý������ڵ��������������д�������������ţ��磬��ͼ��ɫ��ʾ����1����ʱ��˵����1��ȷ�������Ρ�
�����������㹻ʱ����ת�������㹻��ȷ�ϴ��������˴������㹻��ȷ�ϴ���������Ϊ����������������ﵽ�������������������裬���ر���Ϊ�����Ϊ6������رҲ��������Ƶ��Ϊ10���ӣ��ٶ������ܼ�ʱ����(�ӽ��׳ص�������)����BӦ1Сʱ(���㹻ʱ����)������ȴ�ͳ���ף����ʱ����Կ����ǽ�������;ʱ���������������������(P2P����ȫ���㲥�˸ý��ף���Ҳ��������)��ȴ��Զ��������(��Ҫ�㹻��ʱ�䵽�ﹲʶ״̬)��
������Ȼ���ڸý���1��������;��ʱ(�磬����1����ij�����У�����������ij��֧��)����ʱB�����ύһ������x�����ʽ�ת��X�����佻�ײ��֣��ͻ��ǿ����ύ�ɹ��ģ���ˣ�Ӧ�跨������˲��ɹ��������������ȷ���������������ټ�һ����������������ν�����Ա��
����3���������е��Ⱥ��ϵ����Υ�������ʽ�������Ⱥ��ϵ��
��������������x���ڽ���1��������;��ʱ�ύ��ǰ���£�Ҫ���Ա�ڶԽ���x����ǰ�ý���(����1)���ʱ����������������Ĵ���Ӧ���Ͻ��״������н���x�������ں��н���1��������ұߡ�
����ʵ���ϣ��ӳ���ĽǶȿɽ�����ǰ���Ϊ���ϸ���xֻ������ǰ�ý���(����1)�Ѿ�������������������ʱ�����ύ������һ��(�ʽ�����;�����ɼ�)���������ֱ��ȷ�ϵ�����������������ʱ���տ���������������磬����1������6��ȷ�Ϻ�(��һСʱ��)��B����������Ǯ���������п��������տ���������ܱ����տ��ǰ�����ķ��գ����ܱ����տ��ǰʹ�øÿ���(����x)�����óɹ����鷳����ǰ����Ǯ���������ǿͻ��˵ģ�����ͻ���ȫ�����Ļ���д����ǰ���Ĺ�Ա������λ��Dz����١�
������֮�����տ���ԣ��ʽ�ĵ�����һ������;��ʱ�䣬�ͻ�����������������������������磬������ת�����ʽ�������˵����������֧��ǿʵʱ��Ӧ��(���ĸ�ȱ��)��
����7.4 ������
����˵����������ȫ��ȥ���Ļ����ģ�Ҳ���ԣ�ʵ���ϣ�ϵͳ�Ĺ�����(�����)����һ�������������������ƶ������Գ���ʵ�ָù����������°汾���൱��������������ֻ������ִ������(��Ա������ڵ�)�����������Ļ�����֯�����׳Ƶ���ȥ���Ļ�����
���������߽�ϵͳ����Դ�������˹��ڶ������ζȣ���������ԶԳ�������Ż���ά���������Գ�Ϯ�����磬���õ�һ�������������г�Ϯ�ģ��ر��Ƕ�������ͷ���Ľṹ�����ݽ�����(�磬��Ϊ����ǰ��˵����˫ָ����)����������͵õ���һ������������һ���㷢���ɹ�(�㹻������ڵ�����),����ʹ�����һ���µ������������ر�����������������ң��������������ġ�
������������·�(�°汾)���ݾɷ�(�ɰ汾)����������ǰ���ɷ����ɵ����飬���µ����鰴�·����ɣ���������������Ϳ����������ھ��������ϡ������ڹ�Ա�Ƿ����Ļ��ģ���һ����ͳһָ�ӣ����ﵽͳһ�İ汾�������������ͻ�����Ա�ͷ���Ϊ�����֣�һ�������þɰ汾�����Dz������������ھ����ϳɳ�;��һ����ʹ���°汾�����Dz���������ȴ������(�����ķ�֦)�ϳɳ��������������(����ֻ��ij�������鼰��ǰ��)����Ͳ��������������¡��ɷֲ�(���������������γ���Y���ͽṹ)�����ֲַ���ǰ�����۵ķֲ治ͬ�������������������ݵģ��Dz��ɱ���֦�ġ�Ϊ�����𣬽����ֲַ��Ϊ��Ӳ�ֲ���������ǰ���۵ķֲ�Ϊ�����ֲ���(�������Ķ��˵ķֲ棬�һ�ͨ����ʶ���Ƽ�֦)�����磬�ڶԳ���������汾�У����°汾�����������ݽṹ�ı䣬�ͻ������Ӳ�ֲ��������ԣ��ڰ汾����ʱҪ������������������������ĵ��߸�ȱ�㡣
������Ӳ�ֲ���ʹ�������ɳ���Y������(��Ȼ���Ķ������������ֲ���)����ʵ�����γ�����������������Y��������������(��Y�����°�ڹ���)����ʱ���ᷢ��һ����Ȥ����������һ���ʽ���Ӳ�ֲ�ǰ(��Y�����°��)δʹ�ã���ô��Ӳ�ֲ������ʽ�����������Ϻ������ϸ�ʹ��һ�Σ�Ҳ����˵����ĸñ��ʽ���һ�������(�����ܱ�Ϊ������)�������������˫��֧�����½ڵ���������֤��һ�㡣
�����������Ͳ�������������������Ӳ�ֲ������⣬��Ϊ���Ա(����ڵ�)�����ҿɿء���������������������°汾�����������ݽṹ�ı䣬�����ɵ�һ��������(�ɾɸ�ʽ���������)��һ��������(���¸�ʽ���������)��������Ҫ�ֱ���(if else)�����⣬��������(�¾��л���)�ɳ���д����
���������ߵ�����������Ҫ����Թ�Ա������(��֤����������ȷ)���ṩ�������ͽӿڣ�����Ա�Ϳͻ��������ķǺ��IJ��ֵij����磬��Ա���Խ�������Ӳ���Ż��Լ����ڿ���ͻ����Ը��ݸ���ϲ�������Լ���Ǯ�������������������������зǷ��ģ���ò����Ͽ�(�����ߵ�����û�дﵽ50%�����ǹ�������ǰ��)��
�������⣬��ΪӦ�ü��ij���Ա���䲻�漰����������������Ӧע�⣺�������ķ��۸��Իᵼ�²��ܽ��д������ݸ��ĵ�ά��������
������8 ����������ҵӦ��
�������´���ҵӦ�õĽǶ�������һ��������ԭ����Ч�ʼ�Ӧ������
����8.1 ���ˣ���������̬
������������Ϊ���ࣺ����������������˽���������������������ķ�Դ�أ�ǰ���ѳ�����ۡ�˽��������Ϊ���û��Ҫ����Ϊ���������������Ļ���;��ʹ��˽��������Ҫ������Ϣ��ģ�����һ�����ĵ�ǰ���£����߿���ȡ��ǰ�ߡ��ʴˣ����������ص�������������
�������˵���������������ڱ�����ȥ���Ļ�������ȥ���λ�������ô����ȥ��˭��?��ʵ����ָ��ȥ�н����Ļ�������ȥ�н����λ��������н����ڱ����о���ָ����Ա���������������ڹ����������У���Ա������������֯���ͻ��������ι�Ա����Ȼ��������һ����Լ���������������ع�صĹ�Ա����������50%��
������������ʵֻ���������������Ļ������������λ��������н��������в����Ѷ�Ϊ֮�IJ��ԣ���������ļ��������������Ļ����������λ����Ļ����м���Ӧ�ã���Ϊ����Ϣ����չ�����죬�Ѵ����յ���Ϣ�µ������������Ϣ����������������Ϊ���������������µ���Ϣ��(�Լ��ʽ�����Ȩ����)��Ҫ����������������Ϣ�������������Ҫһ������ǽ�������λ��ƣ����������պôӼ������ṩ�����������������ơ�����ͨ�������γ������������ľ��棬������������������Σ�����������������֤��
���������������ṩ��һ�������������ƣ����������
����1�����ݱ����Ŀ��ţ�������������¼���ǽ�����ϸ��������ԭʼ�Ľ�����Ϣ(Դ�ڿͻ��ύ�Ľ���)����Ա�����ý����������(������װ��������)��������˵�����ڽ������ݱ�����ȷ(��֤)�Ļ����ϣ���ͨ������ָ�Ʒô۸ġ�����ǩ���õ�������������ѧ(����ѧ)Ϊ�����ġ�����Ҳͨ��ָ������������������֤�����۸ģ����ԣ��������и�������(�ֲ�ʽ����)�˱���
����2�����ݴ洢�Ŀ��ţ����������ݵ��ݴ�/���֣��磬������ͨ��ȫP2P���㲥��������֤���ݵIJ���ʧ������������ȡ����д���ķ�ʽ���ݴ�/���֡�
����3������Ŀ��ţ�������(����)���ݰ�һ����Ҫ����ɵļ��ϣ��磬�����ظ����ˡ�����˫��֧�����ڹ������ϣ���Ա�䲻��Э�����ˣ����Ǿ������ˣ���Ա��ķ���������Ҫһ����ʶ����(ǰ�����ƪ�����漰������ӻ���)������������ͬ�������и��˵���������������������Ա��(�����Ϊ������)����������ζ����ˣ��Ҹ����٣��б˴����λ�������Ա��ֻ��Э�����˼��ɡ�����������ֻ����Э������������������ڵ��а�ij��Э�����һ��Э����(��ʱ����)��Э���߰�ij��Э������Э�����ڵ���ˣ��������������棺
(1)����һ���Ľ���������������������ص��Ǻ�һ����(ͷ)����ǰһ����(ͷ)��ָ�ƣ�������IJ������ϸ��еģ����������һ����Ӱ��;
(2)��һ�����㷨(Э��)��ʹ�ֲ�ʽ��������ݴ��һ��(�磬��ռͥ�ݴ�Э��)����Ŀ�ģ�һ��ͨ����ͬд�����ﵽ����һ����;����ͨ������д���������ݴ�(����ڸ��˽ڵ�);������ͬһʱ����ֻ��Ψһ��Э��Ա(����)����ˣ����ᷢ������д��ָ��Ӷ��������ظ����ˣ�������������������棺�������飬���н��ɲ��ж�����ش��С�����Э�����������е�������Ϊ��Э����������ǡ��(�����ڷֲ�ʽ���ݿ������һ����Э��)����Ȼ�������������Ƕȣ���������ʶ�������Ĵ���Ҳδ�в��ɡ�
���������������������У�����������䵱�����˹�Ա�������������Գ䵱�ͻ���������ƽ̨����������������������ɣ�
������һ�����������и�������������������Σ�������֯�����ϣ������ζ����ˣ��ټ��ϴӼ������棬������������������������ʹ���˼乲�������ݿ��š�
�����ڶ����ǿͻ��������������Σ���ʵ������ת�Ƶ��ͻ��������������Σ�������ʵ���ֻ���������(�̻�)������������Ҫ�ǿ��г���ܺ�������������֤���ͻ����˶������������Σ��Ϳ��������ַ�ʽ������������һ������������Ϊ�Լ��Ĵ����������Լ���Ϊ����������֤�ڵ���ֱ�ӽ��롣
������������������Ҳ��Ҫ�˽�ͻ�����Ҫ��ǰ����������KYC��(֪����Ŀͻ�)����������
����������������ҵ��֯������Σ������ڼ�������Ϳɴ����磬��ʶ���Ƽ�ΪЭ�����ƣ�����������������Ĺ���Ч�ʡ�
������ҵ����ͨ�����γ���Ϣ�����ʽ������������ʲ����ȣ������������γ���ҵ���(�磬�����ڻ�������Ӧ���̼ң���ܼ����Ż�����)����ҵ������Ź�ͬ���棬�Ӷ����Խ��ˡ�����֯���ˣ����������ˣ�������������������������������һ�����ܵ���ϵ����ֵع������ɹ�ͬ�����µ���ҵ��̬��
����8.2 Ч�ʣ����ؾ���(1)
����ǰ���ѳ�����۹���������Ч��(���رҵļ���ʱ��ΪһСʱ)������������Ҫ������������Ч�ʡ�
��������ǰ��������������ԭ�������ǿ������һ�����ȼ��������ֳ�(����ͼ)��ֱ�۵ط���������Ч�ʣ�

����1���ο�(��Ӧ�ڽ���)�ں����ȴ����������첽�����������ġ�Ϊ���㣬�ٶ��ο͵����Ǿ��ȵġ�
����2����Ʊ���У��ο�ȫ�������Ʊ�����Ŷ�(������㹻�����������ڵȺ��ȫ���ο�)��������ղ��رռ�Ʊ���У�����������ο��ں����еȴ���һ�μ�Ʊ���д���Ʊ���дӹرյ����γ�һ��ʱ�䴰��(��Ϊ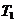 )�����ο͵ľ��Ⱥ�ʱ��Ϊ )�����ο͵ľ��Ⱥ�ʱ��Ϊ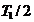 �� ��
����3����Ʊ���е��οͼ�Ʊ�ϳ�(��Ӧ�ڹ���һ������)��Ϊ��ֻ��һ����Ʊ����?��Ϊ������������Ǵ��еġ��Ǽ�Ʊ���е��ο�ȫ����Ʊ�ϳ���ʱ��Ϊ 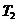 ������ٶ��۹�㹻����װ���Ʊ�����е�ȫ���ο͡� ������ٶ��۹�㹻����װ���Ʊ�����е�ȫ���ο͡�
����4���οͳ����۹�ƻ��ι۹�����й۹�(��Ӧ�ڸ��������˸��˽ڵ㣬ʱ��Ϊ 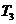 )�� )��
����5�������۹���۹��ص���㣬ʹ��֤�Ѽ�Ʊ���οͲ��ȳ���
�������ݴ�ģ�ͣ����Ƿ�����������Ч�ʣ�
����һ�������ʷ�����
����1���������еļ����������ģ�����Ϊ������С������(�����������ɳ��ٶ�)������ʱ�䴰�ڼ�Ϊ������ ���轻���ȵ�����������������еĵȴ�ʱ��ƽ��Ϊ ;����ʱ�䴰�� ������Ϊ����������Ӧ�ý��е���;���⣬�ɼ�һ�������������������Ļ�����Ӧ���߲������׳���(�磬ƽʱ�������һ����+�߷�������������)����ʱ�� ʵ��С���趨����������ʱ �ɳ�������������Ϊ�����������ʣ�������ÿ����������������ÿ�������ɵĽ�����ΪN����ÿ�����ε������ﵽN��
����2�������������ʱ�䣬��Ϊ������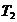 ����������������⣬���ҶԽ��ĺϷ��Լ�����Ƶ��ͻ��ύʱ��(��Ϊ�˽ڵ�ļ�����п�����)������Ϊ�����������ʱ�䣬��Ҫ�����еĹ���÷�˶�����Hash���㡣���⣬���������ص��֪�����Ǵ��еġ� ����������������⣬���ҶԽ��ĺϷ��Լ�����Ƶ��ͻ��ύʱ��(��Ϊ�˽ڵ�ļ�����п�����)������Ϊ�����������ʱ�䣬��Ҫ�����еĹ���÷�˶�����Hash���㡣���⣬���������ص��֪�����Ǵ��еġ�
����3���������һ���Ե�ʱ�䣬��Ϊ������ ���������������Թ�ʶ���Ƽ�ΪЭ������(���Ͻ�����)���� ΪЭ����ڵ��д�������ʱ�䣬�Ƿdz�С�ġ�
����������������Ȼ����ƿ���� ��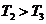 ���� ����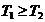 ��Ϊ����Ч�ʣ���ƿ���� ������������״̬���ʿ��裺 ��Ϊ����Ч�ʣ���ƿ���� ������������״̬���ʿ��裺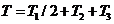 ���� �����ش��С��γ�����ʱ��ͼ�� ���� �����ش��С��γ�����ʱ��ͼ��
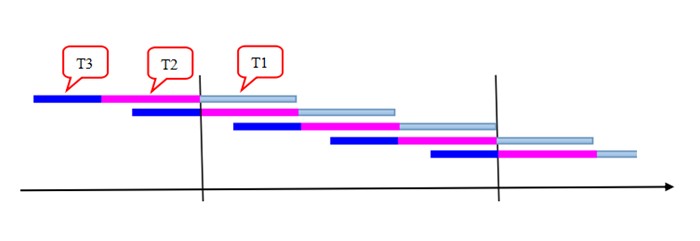
����������ʱ��Ƭ(������)Ϊ3 ���ڼ��൱�ڿ����3�����εĽ�����(ͼ��ÿ����ɫ���߶�Ϊ����)����ǰ������ÿ�����ε�����ΪN���ʅ�����Ϊ3N/3 ����N/ (NΪ������ ��ӳ��������)���������������N�㹻��ʱ�������ʵ�ƿ�������������ʱ��(��Ʊʱ��) ����������������Ӧ�õĴ��ۣ����ļ���(����ʱ�� )���뽻�ױ���û�й�ϵ������Ϊ��֤���ײ����۸����������ӹ���������
���������ο͵�ʱ�仨��(���ļ���ʱ��)
�����ο������ѵ�ƽ��ʱ��Ϊ ��������������ʽ�����Եõ�  ������������ƿ��Ҳ�� ���� һ�������������������������(�����ײ���������ʱ����������÷�˶���С);��һ���������������ء� ������������ƿ��Ҳ�� ���� һ�������������������������(�����ײ���������ʱ����������÷�˶���С);��һ���������������ء�
�������ϣ��������������������ڸ��� �������������ò��в���(��Ҫ����˵���飺����������Ǵ��е�)��ֻ�ܿ��������������ڹ�������(��÷�˶���)����Ҫ�Ǵ�����Hash���㣬������ֵ������Դ�Ӳ���Ƕ��������磬���Կ���ר�Ŷ��ƵĿ�����ר�õ�Hash�����(�������ڿ��)��
����8.3 Ч�ʣ����ؾ���(2)
�����Ͻ������ص�������������Ľ�����Ч�������
�����ٿ����IJ�ѯ��ǰ�������Ѿ��������ظ��������ķ�ʽ�����Ʋ�ѯ��������ֱ�Ӳ������������Dz鸨���⣬���ڴ�ǰ���£��������������Բ�ѯЧ�ʵ�Ӱ�졣
����������ͻ��Ľ����ύ�����ڹ��������ͻ��Ľ����ύ���Ա�Ľ������������������첽������������������Ȼ����Ҳ���첽�����ͻ����Ա(�˽ڵ�)������Щ�������磬�ͻ��ύ��˫��֧������Ա����ͨ�����ظ������Э����飬���ش�������Խ��ĺϷ�����֤���Է���������ڣ������ڼ���ʱ��� �С�����첽�����ͻ����������ύ�ɹ�������Ϊ�����׳ɹ���������������ͻ������ܸ��ܡ���ʵ�ϣ��ڴ������¿����������ġ������ڸý������ĺ����������ԣ���Ҫ�ٵȵ�����ʱ��֮��
�����������Ƕ�Ч����������˷������������������ܵģ���ˣ����Dz��ؾ���Ч�ʣ���ѡ����������Ӧ��ʱ��Ӧ���ؿ۴����ԣ��ܿ�Ч�����⣬�Ӷ��ҵ��ʺϵ�Ӧ�á�
��������Ϊ��Ч�ʽǶ�Ӧ������������Լ����
����1��Ѱ�ҷ��������������ص��Ӧ�á������������ϣ��Կͻ��������첽(�۽Ƕ�);�Թ�Ա����������С��������һ��һ����(��һ������)����Ȼ�����ײ�������ʱ���ᵼ����������ֻ�к��ٽ��ף�����ֻ��һ������(������ֻװһ������)��
����2���ܿ�����������ƿ������������ʱ��T�������ʽ������;��ʱ�䣬������������������ʺ����������磬(����ȯ��)���������Ӧ�ã���Ⱦ��������������ġ�
����8.4 Ӧ�ã�����̽����
��������������Ӧ����ʵ���������������ݵ����Ͻ����ԣ����������ݵ����Ͻ����������������������棺
����1�����ˣ������пͻ�ǩ��������ð��������;
����2��·;��(��������ռ�Ĵ��ݺͿ�ʱ��Ĵ��)��������ָ�ƣ����۸�;
����3����������ʷ�������к���ʱ���(time stamp)��
����Ŀǰ�����������������Ӧ�û������Ǵ�ͳƽ̨Ӧ�õ���ֲ��ѡ����Щ�к�����������(�����������Ͻ����ԣ�)�ͱ�������������(ʵʱ�����ܲ���)��Ӧ�ã����ǿ��ǹؼ�������ټ���Ӧ����������ɫ���Ե�Ӧ�÷���
����1��ת�˻������ַ�ʽʵ��ת�˻�
����(1)���ù�������ת�˻��ƣ��磬���رұ�������ת�ˣ��Է������ڱ��رҽ���ƽ̨��ͨ������������رң������ر�ת���տ���տ�������رҡ���Ȼ�����ַ�����һ���Ļ�����档һ��ʱ��÷��������ʽ����ӹ��������Ƿ�������ѱ���ܻ���ע�⡣
����(2)�������������������ӻ������磬�������У����������������������������ϵͳ�۳��ͻ������������ӻ������տ�����ǩ����ȡ�����ӻ����������ʽ����Լ�ϵͳ�Ŀͻ��ˡ�
����2����ʱ����صĴ����ԣ����������ָ�ƺ�ʱ���֤���¼����ڵ�ʱ����
����(1)ʱ���ǰ���磬�����һ����Ƭ����һ�����������У������������������У������֤��������Ƭ���ṩ����Ϣ�������ɸ�����֮ǰ����������������ʱ�����
����(2)ʱ�����磬���������У�������һ��д��ij����Aָ�Ƶ�ֽ�����˵������������A��ʱ���֮���յġ�
����(3)ʱ�����䡣����������ϵ�������Ϳ��Եõ��¼����������䣬��Ȼ���Ǿ�ȷ�ģ���һ������ȷ�ġ�
����3����֤��˽֤Ӧ�á������Ӽ�¼�������������ԣ�˾����һֱ���������ŷ�����������������������ݲ����۸ģ�����Ӧ������֤�ݱ�ȫ������
����(1)��ԭʼ��¼�����������У��Ա�֤����˾����в����۸ġ�
����(2)����������Ϊ��Ҫ��ļ�¼������ֱ�Ӵ�����ȡ֤�ݡ�
����4��ͨ�����ܺ�Լ������������Ȩ��ת��������
����(1)�����������еļӹ���������Ϣ���ڲ�Ʒ���١��������ڵ��������Ҫ���������������У������̡������̡��������Լ���ܲ��Ź�����Ϣ���γɻ����������Ĺ�Ӧ����̬���磬��ʯ��ҵ���٣���ʯ����������������Ƭ�������ǵ���Ϊ������Ϣ����ת����ͨ������ʵ�֣����в����ߵ�ǩ����
����(2)���ܺ�Լ�Զ������ʽ�֧���Ͳ�Ȩ���ӡ�����������ͬ�����ӻ��ͳ���ִ�л����磬����ǩ�����Զ���ת���Զ�ִ�еȣ���������ͬ����Ӧ��ϵͳ���л��������磬��Ĺ������ܺ�ͬ(������)���Զ�ִ�����漰�����ڡ��������������š���Ȩ����ȣ���ͬ��������֮��ʹ���������ֻ��е�����Կ���ɴ��š�������ΥԼ��Ҳ���Զ��ߵ���ΥԼ����������˾������ȡ�
��������������������һЩ���������ܵ�Ӧ���������£�����Ϊ��ЩӦ���ʺ���������?
����1�������������ĸ������ε����Ͻ������ݣ��������п�繤�������ʵĽ���Ӧ�ã��磬��Ӧ���Ͻ��ס���Ʒ���١���Ȩ��ת��ת�˻���������;��������(������˰���ء����л�������)��
����2���������������ݵĿ��š������ص㣬�����ɹ����(����)��������ϢӦ�ã��磬ҽ���뽡����Ϣ�����桢�칫��Ϣ��������Ϣ��������ȷ�����
����3����������������ǩ�������еķ���ð���������Լ���ʷ��(ʱ���)���������ṩ���й��������ʵ�Ӧ�ã��磬ר�����Ȩ��˾��֤�ݡ��Լ�����Ǽǹ������γɵ���֤��(�磬��Ȩ�Ǽǡ���ͬ������֤����ҵ֤��)��
����4�������������ṩ��ǩ���Ϳ��Ż��ƣ��ž����ܲ������¼��������磬����Ӧ���ڽ���ͬ��Ʊ�ݡ����ڲ�Ʒ(�����Ʋ�Ʒ����Ȩ��ծȨ)�ȣ���ط��ɲ顢���飬��թƭ������١����ҿ���Ϊ�ڲ����շ�����ʩ���ɼ���ؼ����ڿء���ƺͼ�ܳɱ����磬���ָ�ƾͿ����б�һ���������Ƿ��н��ױ���Ա�ġ�
����������
�����ճ������У�����Ҳ�����ҵ�������������Ӱ�ӣ��磬ij��˵������������ĵ�100�����ˣ����������Ϣ�ǣ�����������������������ÿһ���������DNA(�������������е�ָ��)������һ������������һ���ǵ�100��(�������������еĸ߶�)�������˵������һ�ż���������������һ������������ʵ�������Լ����ƾͿ��Եõ����������ٶ���������һ���书���ţ���Ϊ�����˵ı�־��ֻ��������(�������������е�����Ȩ)�����ż�̫��������һ��أ��������˵���ϵ��֧��Զ��һ���̶Ⱦ�Ҫ������֧����̫����(��֦)��������̫������ʷ������Χ���书���ŵ�һ������������?��������ʷ������������ʷ��������Ϣ�ǿ�����֤���ģ��磬˵��ij����������ĵ�100�����ˣ���Ҫ������������ֱ����������������֤����Ȼ����ƭ�ӣ���Ϊ���������(����������)���ٶ�������Ŀǰ�����ܵ�100��������ÿ��������������ʱ��Ҫ��ͷ�飬��û��Ч�ʡ���Ҫ��Ч�ʵظ�����ʷ���ɽ����������Ե���Ϣ���Ի�������ǽ�����������Ϣ��������Ч�ؽ����¡���Ȼ��Ҫʹ�㽲���Ĺ��¿��ţ��ͱ������ij��������������(��ʶ)��
�����������������������֮��������ѧϰ���������������е����˼�룬����ͨ���ķ�ʽ�ܽ���ġ���Ϊһ���㷨�����ߣ������Ĺ����У�������ӽ��ǻ��ڳ���Ա��ע���㷨����ϸ�ڲ���Ҳ�������Լ���һЩ�뷨�����Եĵط�����ָ����
|