数据湖的概念指出,数据无需加工整合,可直接堆积在平台上,由最终使用者按照自己的需要进行数据处理。而数据仓库建设强调的是整合、面向主题、分层次等思路。可以说,数据湖建设思路从本质上颠覆了数据仓库建设方法论。
中国人寿股份有限公司研发中心 张新宇
近两年在大数据管理领域中争论最多的恐怕要属数据湖(Data Lake)的概念了。虽然Pentaho的CTO James Dixon 2010年就已经提出了这个概念,但直到最近两年才引起业界的热议。“数据湖”概念涉及数据架构、应用模式以及数据管控等多方面的问题。James用了一个形象的比喻来描述数据湖:“如果把数据集市看做一瓶饮用水,数据湖则是未经处理和包装的原生状态水库。不同源头的水体源源不断流入数据湖,带来各种分析、探索的可能性。”
这一概念带来了几个延伸性问题:一是大数据管理是否还需要数据架构规划,尤其是业界已经非常擅长和熟悉的数据架构层次?二是Schema On Read和Schema On Write提出的问题,即对于无结构的原始数据,是在其进入大数据平台之初就通过各种方法确定其Schema(简表),还是留给数据使用者自行解决。三是数据在使用之前是否需要质量检查,是否需要进行标准化等处理。
由上述分析可见,数据湖的概念指出,数据无需加工整合,可直接堆积在平台上,由最终使用者按照自己的需要进行数据处理。而数据仓库建设强调的是整合、面向主题、分层次等思路。可以说,数据湖建设思路从本质上颠覆了数据仓库建设方法论。两者差异如图1所示。
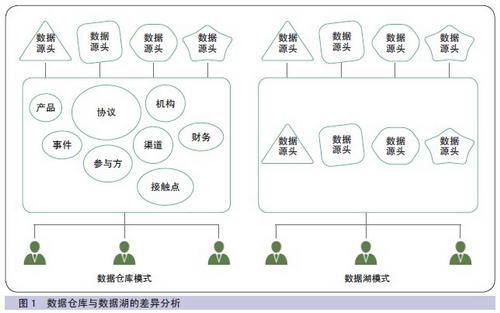
在数据仓库模式下,数据需要清洗、转换及整合,而在数据湖模式下,这些工作由最终用户按照自己的需要处理。
事实上,由于企业发展的历史、现状以及IT治理模式等的差异,并不存在一个放之四海皆准的数据架构蓝图。本文通过对数据使用需求差异进行分析,探讨大数据时代的数据架构设计。在探讨之前,需建立两个共识:一是企业内部的不同条线,不同部门的用户之间,对于数据应用的深度和广度是有差异的。这种差异带来了使用模式、数据基础和时效性要求等方面的不同要求。二是企业IT系统建设基于一定预算,成本可控。如果投入无限大,那么数据架构的探讨就失去意义。
一、数据使用需求的差异
无论数据架构如何设计,目的都是为了满足最终用户的需求。因此,在讨论大数据时代的数据架构设计前,首先应该明确企业内部对于大数据的应用究竟可以从哪些角度对需求进行梳理。
1.固定与灵活:使用模式的不同要求
尽管固定报表应用模式已经存在多年,而新的数据使用模式又层出不穷,但报表由于其简单明了的特点,目前依然是企业内部各种数据应用形态的主力,尤其是针对各级管理人员。这种模式对数据使用的要求是固定的,加工路径也是固定的,因此可以通过各种预处理和预先加工来对数据进行处理,从而提升查询速度。基于上述特点,技术人员可以事先对所有的数据表进行设计,对程序进行优化。
联机分析是针对业务分析的一种使用模式,当通过报表发现业务问题时,通常需要从不同角度进一步分析问题产生的原因。这类分析可能没有预先确定的模式和路径,需要在大量的数据中通过更加灵活的方式进一步探索,通常通过OLAP和即席查询的方式完成。OLAP在预先定义的语义模型上进行进一步分析;即席查询允许用户在更加底层的明细数据上通过编写SQL语句来进行分析。
数据科学家所做的探索性数据分析工作则更加灵活,数据的来源可以是外部、非结构化甚至半结构化的数据,数据处理则可以采用各种编程语言,其灵活度远远超过SQL语句的承载能力,其分析的主题甚至可以是事先没有设定的,从对各种数据的不断探索中寻找发现问题的灵感。
2.统一与独立:数据基础的不同要求
很多用户希望在统一的数据基础上进行数据应用,这种方式的好处体现在:用户无需为来自不同系统的数据建立关联关系;无需进行数据清洗和转换;无需理解每一个数据源系统的结构和内部关系;从不同角度进行分析时,可以得到不同的结果。
与之对应的是,统一的数据基础通常为满足一些应用的共性要求对数据进行相应的处理,如数据清洗、代码标准化或过滤掉质量不合格的数据。这种共性化的处理使得一些需要使用原始数据的用户无法使用,一些代码转换可能丢失了部分信息,一些整合可能使得数据无法还原。有些用户希望拥有自己独立的基础数据,直接使用原始数据,而不是转换后的数据。在风险管控和审计领域,这种需求更加明显。
3.稳定与敏捷:面对变化的不同要求
不同应用场景和不同业务处理系统对数据的要求也不同,概括而言,主要有两类:一是希望能够通过数据架构的设计保持应用稳定,尽量屏蔽各个应用系统的变化对各类数据应用的影响。二是希望能够迅速跟上系统的变化,保持敏捷。两类要求都有其合理性,尽管并不是每个应用的使用者都关心源应用系统的变化,但如果不对变化进行管理,对所有应用都会产生影响。
4.时效性的不同要求
企业内部的不同应用,对时效性的要求也不尽相同。有些应用对数据有准实时性要求,如业务监控类应用、实时营销类应用和事件侦测类应用等;有些应用对数据时效性要求为半日/隔日;有些应用旬和月度即可。针对不同的时效性要求,数据基础、数据加工的路径和采用的技术也不相同。
随着企业数据应用的成熟度不断增加,数据时效性要求的差异也会越来越明显。数据架构就是要随着要求的不断变化而进行调整。下文从技术角度分析需求差异对数据架构提出的要求和带来的挑战。
二、两种数据架构设计
数据架构及其技术实现都是服务于数据使用需求的,而使用需求上的差异对于技术实现的要求不同,需要采用各种变通的技术架构满足要求。本文重点分析不同数据使用要求对技术平台的不同要求以及两种数据架构的适用场景。
1.固定、统一的要求需要层次化的数据架构
使用模式上,无论是固定报表还是各种形态的联机分析,从数据架构的角度看,都可以采用层次化的数据架构满足要求。这种模式成本最低,基础数据和应用指标的一致性最好,以经典三层架构设计为代表。
第一层为同源/贴源设计:这一层又称为“数据缓冲层”、“临时数据区”或“数据预处理层”,在这一层中保留最为原始的数据。一些设计将部分数据清洗和格式化工作放在这一层;另一些设计不在该层进行哪怕最基本的数据清洗和格式化工作,目的是满足用户对数据清洗和格式化的不同要求。对于半结构化数据,应用访问日志数据在第一层中是否需要格式化为关系表的方式,在不同的实践中有不同的数理。而结构化数据,在从交易处理系统中被抽取出来后,不做任何转换直接保存在这一层中。
第二层为整合设计:包括多个数据来源的数据整合、代码转换和标准化、类型及格式的统一和转换以及分类体系和业务实体的统一、建立来自不同系统的数据之间的关联关系等。整合消除了多个数据源的不一致、为数据建立连接关系,形成了客户、交易、合同、产品等不同的数据主题,为后续的数据使用奠定基础。
第三层为面向应用主题的设计:通常在这一层中,建立起针对某些应用领域的分析指标和体系。如面向营销和客户分析的各种类型的分析指标、客户特征和标签;面向风险的各种风险指标;面向绩效管理的各种业务统计指标等。这一层更加注重统计指标的标准化,包括指标口径和定义、指标的一致性等。
2.灵活、独立的要求需要扁平化的数据架构
层次化的数据架构尽管带来了诸多优势,但在面对灵活、独立的数据使用要求时,也带来了一些问题。
首先,数据整合带来了数据使用上的复杂性。其次,可能丢失信息。如在代码标准化的过程中如果丢掉了原始代码,则可能造成信息丢失。而若保留原始代码,则会带来大量的冗余。最后,整合的设计使得数据管理变得笨重,源系统变化,涉及整合规则、数据模型变化以及大量的数据迁移,使得数据架构难以快速调整。
而数据湖的思路,正是把上述问题留给了最终用户,由最终用户按照自己的要求自行解决。某种程度上,数据湖并不是一个技术概念,而是数据管理的另一种思路,对于IT技能较强、数据使用需求灵活、习惯于不走寻常路自行钻研业务问题的用户来讲,不失为一种可借鉴的方法。
3.两类数据架构的比较和分析
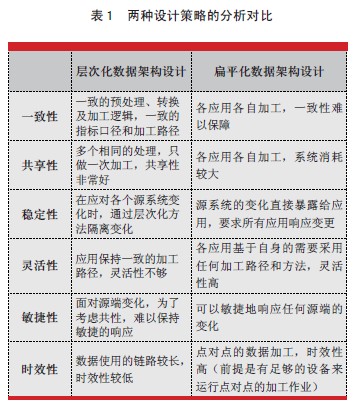
两种数据架构设计在面对不同的数据使用需求时所表现出来的特点也不同。表1为两种设计策略的分析对比。
通过表1的分析,不难看出,在面对不同的数据使用要求时,不同的加工设计方法有其适用的场景和特点,而数据架构设计的思路就是结合企业内部不同要求的紧急和重要程度进行权衡与选择。
三、两种数据管理模式
谈到数据架构设计,有一个无法回避的问题是数据管理模式的设计策略。在关系型数据库中,为了清晰地表达一个确定的业务含义,采用E-R模型作为数据管理的基础,通过模型设计的方法建立数据模型,再通过应用程序将数据写入预先定义好的表结构中。
这种方法虽然已为人所熟知,但却存在明显的缺点:①数据在写入之前就必须有其明确的定义。在关系型数据库中,一个明显的例子是,必须有一个Create Table语句建表,才能有Insert语句写入数据。这个Create语句中,就是事先确定的数据格式。②1个表中的所有行都必须遵循同样的格式。为此,关系型数据库引入空值概念表示某条记录没有某一属性。③当某条记录增加一个属性时,需要给已经在数据库中的所有记录增加该属性。
上述缺点在迅速变化和事先不能确定数据格式的场景下显得尤其突出。业界将这种方式归为Schema On Write,即在数据写入时就需要确定其格式。与此对应的方式为Schema On Read,即在数据访问时,由数据访问者来解析和确定数据的格式,写入者并不关心其是否有一致、统一的数据格式。
Schema On Read 方式具有以下优点:①降低数据保存的成本,无需开发即可保存。②降低数据产生和使用之间的延迟。③给予最终用户最大的灵活度来处理数据。④允许用户保存非结构化、半结构化的数据。⑤对于现在不需要处理或者无法处理的数据,保留原始数据供未来使用。⑥同一份原始数据上,不同的用户可能有不同的理解。
Schema On Read方式的缺点为:①不同用户多次解析数据造成计算资源浪费。②有些数据如果不在写入的时候遵循一定的格式,在使用时不一定能够解析其格式。③用户在使用时,不得不先花时间去解析数据的格式。
以上分析说明,Schema On Read和Schema On Write两种方式有其不同的优缺点。在两种不同的数据架构设计策略下,在什么样的场景下使用哪种数据管理模式需要依据使用要求决定。整体来讲,针对原始数据,采用Schema On Read管理模式进行数据保存,针对稳定性较高,相对固定的应用,采用Schema On Write的方式将解析后的数据进行保存,两者方式相结合是比较可行的方式。
本文从四个不同角度分析企业内部数据使用需求差异,从中可以看出,单一的数据架构设计方法难以满足所有的应用要求。某种程度上,企业数据架构设计与城市交通规划类似,既有大众出行的共性化需求,也有点对点的个性化需求,还有为特殊需求而设置的应急车道。城市交通问题需要地铁、公交、出租车、自行车、步行等一系列的综合手段来解决。大数据时代数据架构设计的方法也大同小异,采用层次化与扁平化数据架构相结合的方式,制定相应的准入原则;从企业的实际情况出发,分析不同需求的紧迫性和能够带来的业务价值,实现投入/产出的最佳平衡。FCC
|