����������ϯ��Ϣ�� ������
�������пƼ��������������� ������
��ӯ�Ǵ�(����)�Ƽ�����˾ ���� ���� ��� ���岩
�˹����ܴ�ģ�ͼ����ij��֣�������������ľ��죬Խ��Խ�����ҵ���ٲ��֣�Ͷ���ģ���з����У��⼤���˸��и�ҵ��ͨ���˹�����(ArtificialGeneralIntelligence,AGI)����̽�������顣��ģ�ͼ����Ŀ��ٷ�չ��ΪԽ��Խ�����ҵ�����˱�����������ҵһ�������Ŵ�ģ�����ܳ�������������һ����ҲҪ����Ͷ������������أ�����˽�л�����ȫ�ɿ�Ҫ���������ƽ����ֻ�ת�͡����ܻ���չ��
������ҵ�����Ⱥ�����IT��ά��ϵ���Զ�����ƽ̨�������ܻ���չģʽ����������һ��ϵͳ��������ά���صĿɳ�����չ֮·��������������������渳�ܡ����������������ά�����������������ά����Ϊ����������ء����̹������Զ����ȹ�����һ��ġ��ࡢ�ܡ��ء�������άƽ̨������ϻ���ѧϰ�����ݷ�������������������ά����������Ŵ�ģ�ͼ������������죬������ά�����µķ�չ�Σ������Ŷӻ���˳Ӧ������ƣ��о�̽����ģ��������������ά�����ںϵ���ģʽ��
һ����ģ������ά�������
��ģ�Ϳ���Ϊ��Ϣϵͳ����Ķ�����ڸ��ܣ��������������ϵͳ��ơ�ϵͳ��������������ԡ�ϵͳ������������ά�ȣ��Ӷ������з���άһ�廯�����ܻ�ˮƽ���������ֽ��ڽ���������Ч�������Ŷ��ڴ�ģ�����������̽��跽������ˡ�5D��������(��ͼ1��ʾ)�����������(Demand&Requirement Analysis)��ϵͳ���(Design of System)��ϵͳ����(Development of System)�����������(Debugging&Testing)�Լ���������ά(Deployment&Operations)��
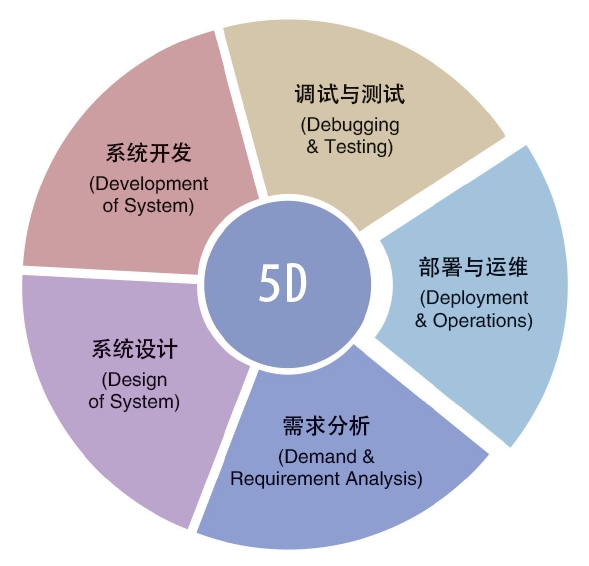
ͼ1 ��ģ������ά�ġ�5D��������
�ڴ˻����ϣ������ŶӾ۽�IT��ά����������ά�����ض�������������6R2��Ӧ�ÿ��(��ͼ2��ʾ)���ÿ�ܰ�������֪ʶ�������ǿ���ɼ���ʵ�ֵ���ά֪ʶ�ʴ𡢻��ڹ�ϵ�����ݿ������ǿ���ɼ���ʵ�ֵ���ά���ݲ�ѯ�����ڹ�ϵͼ������ǿ���ɼ���ʵ�ֵ���ά��ϵ���ݲ�ѯ�����ڡ�������+������ǿ����+˼ά��������ʵ�ֵ���ά���϶�λ�봦�÷����Ƽ������ڡ�������ǿ����+��ʾ�ʹ��̡�����ʵ�ֵ���ά�������ɡ����ڹ����ھ�ͻ���ѧϰ����ʵ�ֵ���ά����Ԥ��ʶ��
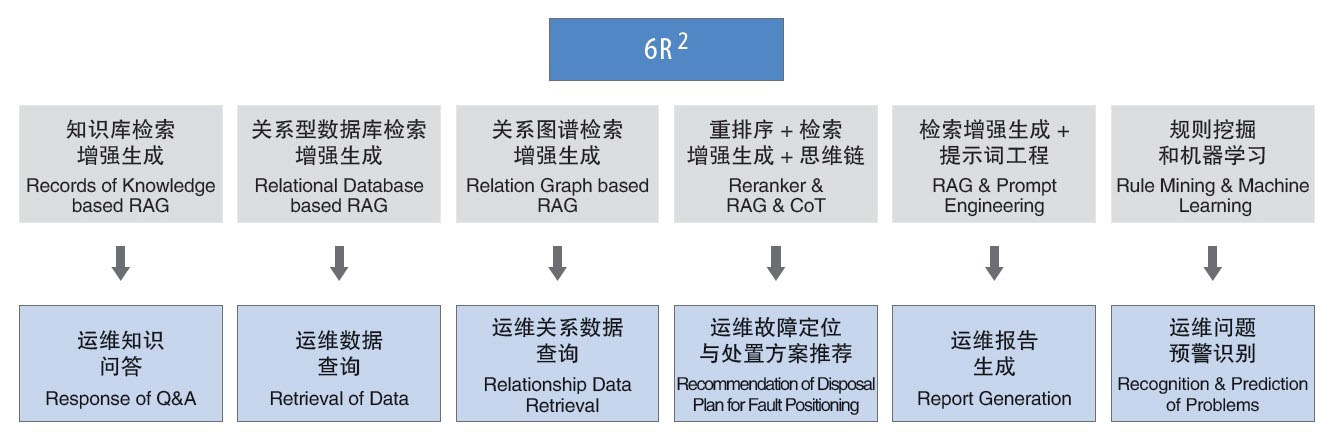
ͼ2 ��ģ������ά�ġ�6R2��Ӧ�ÿ��
������ģ������ά��������
�����Ŷ����м���ʽ��ģ�ͼ�����Դ�����á���Լ���䡢������չ�������ȡ��ȶ����С��������ɿط�ʽ������������ģ��������������ʾ�ʹ��̡�������ǿ���ɡ�������˼ά������Сģ���ںϵ����������������˷�����IT��ά�����AIӦ�ã��似������ϵͳ�ܹ���ͼ3��ʾ��
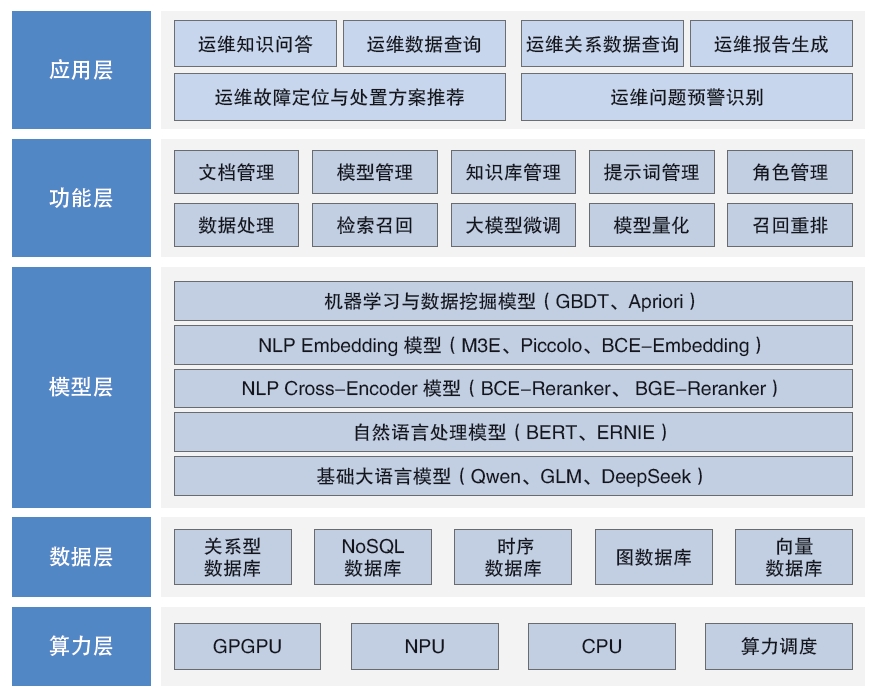
ͼ3 ��ģ������ά��������ϵͳ�ܹ�
1.��ģ������ά��������ϵͳ�ܹ�
��ģ������ά��������������ϵͳ�ܹ��ɷ�Ϊ������㡣
�����㣺��������������Դ(��GPGPU��NPU��CPU��)����������ģ�飬�ṩ��Ҫ�ļ�������֧�֡����У���������ģ�鸺����Ч�ط��������������ȷ����Դ�ĸ�Ч���á�
���ݲ㣺��������ʹ洢��άϵͳ����ĸ�����Ϣ��Դ���������������û��ֲᡢ����������(FAQ)����ά������Ϣ����(CMDB)ϵͳ�����ü����ϵ��Ϣ��ϵͳ����ָ�ꡢϵͳ�澯���¼�����������������ϱ��浥�ȹؼ���Ϣ������������Ϣ�����˴�ģ������άӦ�õ����ݻ�ʯ�����⣬���ݲ�Ҳ����洢��������Ӧ�õ��м������������ݣ����������Է�����벻ͬ�����ݿ��С����ڽṹ���ı������ݣ�ʹ�ù�ϵ�����ݿ���б���;���ڷǽṹ�����ṹ�����ݣ���ʹ��NoSQL���ݿ���б���;������Ҫչʾ�����ʱ������ݣ�����ʱ�����ݿ���б���;������Ҫչʾ�ͷ���ʵ��֮�������ϵ�����ݣ�����ͼ���ݿ���б���;�������漰���ƶȼ��������ݣ�������������ݿ���б��棬����ϴ�ָ���ԭʼ���ݣ������������ģ�ͽ���ת����������ʽ�����洢���������ݿ��У��Ա������ģ�ͽ��и��������ı�ƥ�䡣
ģ�Ͳ㣺��������ģ��ʵ�����������ı���������Embeddingģ�͡������ı��������Cross-Encoderģ���Լ��������Ȼ���Դ���ģ�͡�����ѧϰģ�ͺ����������ܽ�Ļ�����ģ�͵ȡ�����ģ��Ϊ������Ӧ���ṩ��ǿ����������������������
���ܲ㣺���Ͼ���Ļ�������ģ�飬�����Žӿڹ�Ӧ�ò���á����У�ģ��������ģ�͵��������ڹ������������������������رա���չ�����µȲ���;֪ʶ����������˶�������ģ�͵ĵ����Լ������ݿ�Ľ���;��ʾ�ʹ������ɫ�����������ݿ�Դ�ģ�Ͳ�ͬ������ʾ�ʽ��й���;�����ٻظ���ִ�����������ʹ�ͳ���ݿ���������ٻ��������������;���ٻ����ſɵ���Cross-Encoderģ�Ͷ��ٻ����ݽ���������
Ӧ�ò㣺�ò�����Ծ���ҵ���������������û��Ķ�����Ӧ�á����Ӧ�����ù��ܲ����ṩ�ķḻ�ӿںͷ���ʵ���˴������ռ�����������Ϣ����������������������һϵ�����̻�������
2.��ģ������ά�����ص�
��ģ������ά����Ӧ�û��������γɵĴ�ģ��������������ʾ�ʹ��̡�������ǿ���ɡ�������˼ά������Сģ���ںϵ�����������������Щ���������Ͻ�������Ծ��峡��������Ż�����Ч������ϵͳ�����ܺ��û����顣
(1)������ά����Ԥ������������ھ�ģ��
Ϊ����ǿ��ά����Ԥ�������������Ŷ�����ʾ�ʹ��̻������뾭�������ھ������ѧϰ�еĹ��������ھ�����㷨ģ�ͣ����ø�ģ������Ĺ���������������ʾ�ʡ���Щ���ɵij�����������߽��������Ϊ��ģ��˼ά����һ���֣���ϴ�ģ�ͺ������������裬�γ��������������̡����ַ��������ܰ�����ά��Ա��ǰ����DZ�����⣬�����ṩԤ���ԵĽ����֧�֣��Ӷ�ʵ����ά�����Ľ���������Ч��
(2)Document2Question2Question����
ԭ��RAG�����Ƕ��ĵ��з֣��ٶ��зֺ���ı���(Chunk)������������֮������ƥ���Ӧ���ʾ䣬���Խ��俴��һ��Document2Question�����������Ŷ��ڴ˻����Ͻ������Ż�����������ΪDocument2Question2Question����һ�Ľ�ʹ��IT��άϵͳ�ܹ�����AI��ģ��������������зֺ���ĵ�Ƭ�Σ���������Ԥ������һϵ�к�ѡ�ʾ伯;���ڸ�����ѯ����������Ԥ���ɵĺ�ѡ�ʾ�֮���ŷ�Ͼ�����������ƶ�(Cosine Similarity)�����Ի�ñ�ֱ����ԭʼ�ı���ƥ���Ϊȷ�Ľ�������ַ������������˼���Ч����ʹIT��άӦ���ܹ���ø�ȷ������صĽ��������
(3)��Ч��ϼ�������
�����ݼ������棬�����Ŷӳ��˲��û���������ŷ�Ͼ��뼰�������ƶȽ�������ƥ���⣬������һ����BM25�㷨�ļ����⡣���ֻ�ϼ������ƽ�������ߵ����ƣ����ܿ��ٶ�λ����ĵ�������ͨ������������������ȣ�ȷ���û��������صĽ��������
(4)Reranker���������Ż�
��Reranker�������棬�����ŶӸ��ݾ���Ӧ�ó���ʹ�ò�����ģ����ΪCross-Encoder������ģ�͵IJ��䡣��Щ��ģ���ܹ���Ч�����ӵ�����ģʽ����һ������Reranker�������ȷ�ԡ����Cross-Encoderģ�ͣ���Щ��ģ�����������������ڲ����ӹ�����㸺��������£���ߴ�ģ��������ȷ�ԺͿɿ��ԡ�
����һϵ��������Եļ����Ż���ʩ����Ч������IT��ά���Զ��������ܻ�ˮƽ��Ϊ��ά��Ա�ṩ�������ܡ���ݡ��ɿ��ļ���֧���뱣�ϡ�
������ģ������ά����Ӧ��
�ڡ�5D���͡�6R2�������ۼ���Ӧ�ÿ����ϵ�£������Ŷ���ѭ��С�����ܡ������ѡ��ij����滮ԭ���ƽ���ģ������ά����Ӧ�ã�������ά��Ա�ճ�������
1.��ά֪ʶ�ʴ�
��ģ�;��н�ǿ�������������������õĽ���Ч�����ܹ�����ά��Ա������Ȼ���Խ������ճ���ά��У���ҵ���л����˴�����άϵͳ���û��ֲᡢ���������ĵ����¼����̴�������ĵ�����������Ϊ˽����ά֪ʶ�������Ŷ�����ͨ���������ݿ��Ƕ��ģ�ͽ���ά֪ʶ���ݽ�����Ƭ���ܽᴦ�����γɹ���ģ�͵��õ�֪ʶ�⣬�����ô�ģ��Ԥ����Ӧ��ʾ�ʹ��̣����RAG�������ȸ���������ά֪ʶ���������ɻش𣬸��ƴ�ģ�ͻþ�����;����ڴ�ģ�͵���ά֪ʶ�ʴ�������װ��Ӧ�ã�������IT��άϵͳ�У����û������������ô�ģ�ͼ������������ɾ����ض���ɫ��ɫ�����ݻظ����ش�Ա����ά����֪ʶ���⣬�ﵽ������ά�ͷ�������Ч�����������ڼ䣬�����Ŷӳ�ȡ��1000����ά�ʴ��������־����ģ�����ɵ�֪ʶ�ش�����𰸵�˫���滻����(BLEU)ֵΪ0.643�������ٻ��ʵ�ժҪ��������(ROUGE)һ���Ϊ������ָ�꣬ROUGE-1��Ҫ��ע���ǵ������ʼ�����ص������ROUGE-2�����������������ʵ��ص������ROUGE-L����������������(Longest Common Subsequence,LCS)�����ɴ𰸵�ROUGE-1(F1)ֵΪ0.832��ROUGE-2(F1)ֵΪ0.736��ROUGE-L(F1)ֵΪ0.817;ͬʱ���ش�ȷ��ԼΪ87%�����и�Ƶ�������ֻش������ԼΪ92%��
2.��ά���ݲ�ѯ
CMDBϵͳ��¼��������Ϣϵͳ��ʹ�õ�IT��������ϵ��Ϣ������ά������Ҫ��֧��ϵͳ��CMDBϵͳ�ײ���ù�ϵ�����ݿ�(Relational Database)��ͼ���ݿ�(Graph Database)��ϵ��ںϼܹ�����Ԫ������Ϣ�洢�ڹ�ϵ�����ݿ��У����������ϵ��Ϣ�洢��ͼ���ݿ��С���ͳ������Ϣ��ѯ��ʽ���û����˽�������ı��ṹ��������Ϣ����ͨ�����ñ������дSQL��ѯʵ�֡������Ŷӽ�CMDBԪ������Ϣ��RAG����ʽ���ģ�����ϣ�ʹ��ģ����Ȼ����תSQL(NL2SQL)������ǿ���ܹ������û�����Ȼ���Բ�ѯ��ͼ��ʶ�����ѯ�еĹؼ�ʵ�塢���Ժ���������Ϣ;�����ڴ�ģ�͵�NL2SQL������װ��Ӧ�ã�������CMDBϵͳ�У����������ı��ṹ��������Ϣ����RAG֪ʶ�⣬���ô�ģ�ͽ��û�����Ȼ��������ת��Ϊ��Ӧ��SQL��ѯ��䣬�����û�����Ԫ�������д��ѯ���Ĺ��̣����ڶ��û���ͼ�����ⷵ�ز�ѯ�����Ϊ�û��ṩ�����ܵĽ�����ʽ��ʹ�ò�ѯ��ά���ݱ�ø���Ч����������֤��NL2SQLִ��ȷ��(Execution Accuracy)ԼΪ85%����ȴ�ͳ�������ñ��������ݲ�ѯ���ȱ����˽ϸߵ�ȷ�ʣ�Ҳ�����˲�ѯ��Χ����������ά���ݲ�ѯЧ�ʡ�
3.��ά��ϵ���ݲ�ѯ
CMDBϵͳ����ͼ���ݿ����IT������֮��Ĺ�ϵ���ݣ��ṩ���ù�ϵ�IJ�ѯչʾ���ܡ���ͳ��ʽ���û���Ҫ�˽���ά�����ʲ���ͼ�����������ݹ�ϵ��Ϥ���ܽ������ù�ϵ�����IJ�ѯʹ�á������Ŷӽ�CMDBϵͳͼ���ݿ�����ݽṹ���ģ������,ʹ��ģ����Ȼ����תͼ���ݿ��ѯ����(NL2Graph)��������ǿ���ܹ������û�����Ȼ������ʽ����Ĺ�����ϵ��ѯ������ת��Ϊͼ���ݿ��ѯ���ԣ�ʵ����ͼ���ݿ��н��и�Ч�IJ�ѯ��������������ʹ���û����������˽�ͼ���ݿ�ľ���������ݽṹ�����ܿ��ٻ�ȡ�������Ϣ�����ͬʱ�������Ŷӽ����ڴ�ģ�͵�NL2Graph������װ��Ӧ�ü�����CMDBϵͳ�У��Ӷ�ʵ�ֻ���ͼ���ݿ�Ĺ�ϵ���ݲ�ѯ����Ӧ�ã���һ������CMDBϵͳ�û�ʹ�����顣�ڲ�����֤�����У�����Ӧ��ϵͳ������������Ӧ������������ݼ���ͨ��A/B���ԣ���ȴ�ͳ���ù�ϵ��ѯ�����ڴ�ģ�͵�NL2Graph��ѯЧ��������15%��
4.��ά���϶�λ�봦�÷����Ƽ�
����������Ϣϵͳ��ģԽ��Խ��ϵͳ֮����ʹ�ϵԽ�����ӣ�����ڸ��Ӷ���IT�����У�����ʵ�����Ϸ��֡����϶�λ������ֹ��һֱ����ά������ѵ㡣��ˣ������Ŷ��Ƴ���ר�Ҿ���+��������+�б�ʽAIģ�͡��Ĺ������ܷ���ģʽ�������������ݹ�ϵģ�ͣ��ڹ��Ϸ���ʱ��������·�е������ε��ù�ϵ��Ӧ�������Ӳ���豸������ܹ���Ϣ��������ʽ����չ��;������ά����ƽ̨ʵʱ������ݣ���������ȫ����ջ�Ĺ۲����ģ�ͣ�����ָ����㡢Ӱ���ǩ��ר�Ҿ������ϵķ�ʽ���ۺ�Ӧ�����ܷ�����������Ӳ�����Ϸ�����������Ϸ���������ʵʱ���������ʵ���������϶�λ��
�����Ŷ�ͨ�������ģ�ͷ��������������˹���ʽ�ܽ�ר�Ҿ��飬�ɴ�ģ��������˼ά��ʵ�������������ۺ���Ϣ���ж�ά�ȷ��������ɹ��϶�λ����;ͨ���Դ�ģ���ܽ�Ĺ��϶�λ�������ݽ��б�עѵ������������ģ���϶�λ����ȷ��;���ϵͳ�Զ���Ӧ������ִ�м�¼���мӹ����������ģ�����ϣ�Ϊ��ά��Ա�Ƽ��Զ���Ӧ�����ߵĴ��ý��飬�ڴ�ģ�����£���һ��ʵ�֡��ˡ���Ϣ�����á��ĸ�ЧЭͬ��
5.����������
���ж�����֯�����¼������ᣬͨ������Ϣϵͳ���Ͻ��и��̡��ܽᾭ�顢��һ��������������δȻ�����á�����ճ���ά������У����ڶ�����Ҫ������Ϣϵͳ���Ϲ��̡��˹��ܽ��γ������¼�������������Ŷ����ô�ģ�͵��ܽ�������ͨ�������ɫ�ķ�ʽԤ����ʾ�ʣ���Ϲ��Ϸ����δ�ģ�ͽ��յ�����Ϣϵͳ������Ϣ����ظ澯���ݣ�����IT����̨�ļ�¼��Ϣ�������ɴ�ģ�����ɹ����ܽᱨ�档������֤�����У����ڴ�ģ�͵���ά�������ɲ�����ԼΪ95%���ɴ��������ά����Ч�ʡ�
6.��ά����Ԥ��ʶ��
�����ŶӲ���ʱ��������������һϵ���б�ʽAIСģ�ͣ��Լ�ظ澯���ݽ��д�����ͨ����̬��ֵԤ������/��ָ���쳣��⡢��־�쳣ģʽ���������ܼ���������������ظ澯����Ч�ԡ���ʱ�ԡ����ͬʱ�������Ŷӽ�����Сģ�����ģ���������ϣ���������Ĺ����������������������ض���ά�澯����һʱ���Ƿ��������쳣�澯���з���������Ԥ��ʶ��δ�����ܷ����Ĺ����쳣�澯���������������м�ظ�����Ԥ��ǰհ�ԣ�ʵ����ά����Ԥ��ʶ�𣬱�����ά��Ա��ǰ���룬�ӿ���Ϸ������õ���Ӧ�ٶȡ�
�����Ŷӻ��ڡ�5D���͡�6R2�������ۼ�Ӧ�ÿ����ϵ����չ��ģ������ά����Ӧ���о����������˿ɸ���IT��ά����ġ�7��24����������Ӧ�ã�Ϊ������ά֪ʶ�ʴ���ά���ü���ϵ���ݲ�ѯ����ά���Ϸ�����λ����ά���÷����Ƽ�����ά�������ɡ���ά����Ԥ��ʶ��ȳ������ܣ�������ά����Ч�ʡ�
���Ŵ�ģ�ͼ����ij��켰���ڽ������������Ӧ�ã������Ŷӽ���ȡ�����Ż�˼·��һ�Ǻ�ʵ������������������ϸ�ұ���Ԫ���ݹ�����Ϊ�����������ܷ�չ�Ļ������ϣ����������Ȼ��������SQL��ȷ��;���ǽ��������Դѡ������Ĵ�ģ�ͣ���չ�����Ĵ��ڳ���������������ļ���Ч����ʵ�ָ��õĹ滮����;�����о�����������ĸĽ�������ʹ��ģ�;߱����⡢��֪���滮�������ʹ�ù��ߵ��������������ܻ�ˮƽ������ȫ�����ֻ�ת�͡����ܻ���չ������ʵ��ǰ��
���������пƼ������������������������������ΰ������𩣬��ӯ�Ǵ�(����)�Ƽ�����˾������������ȡ����������Ա������й��ס�
|